データベースのシャーディングを簡単な英語で説明する
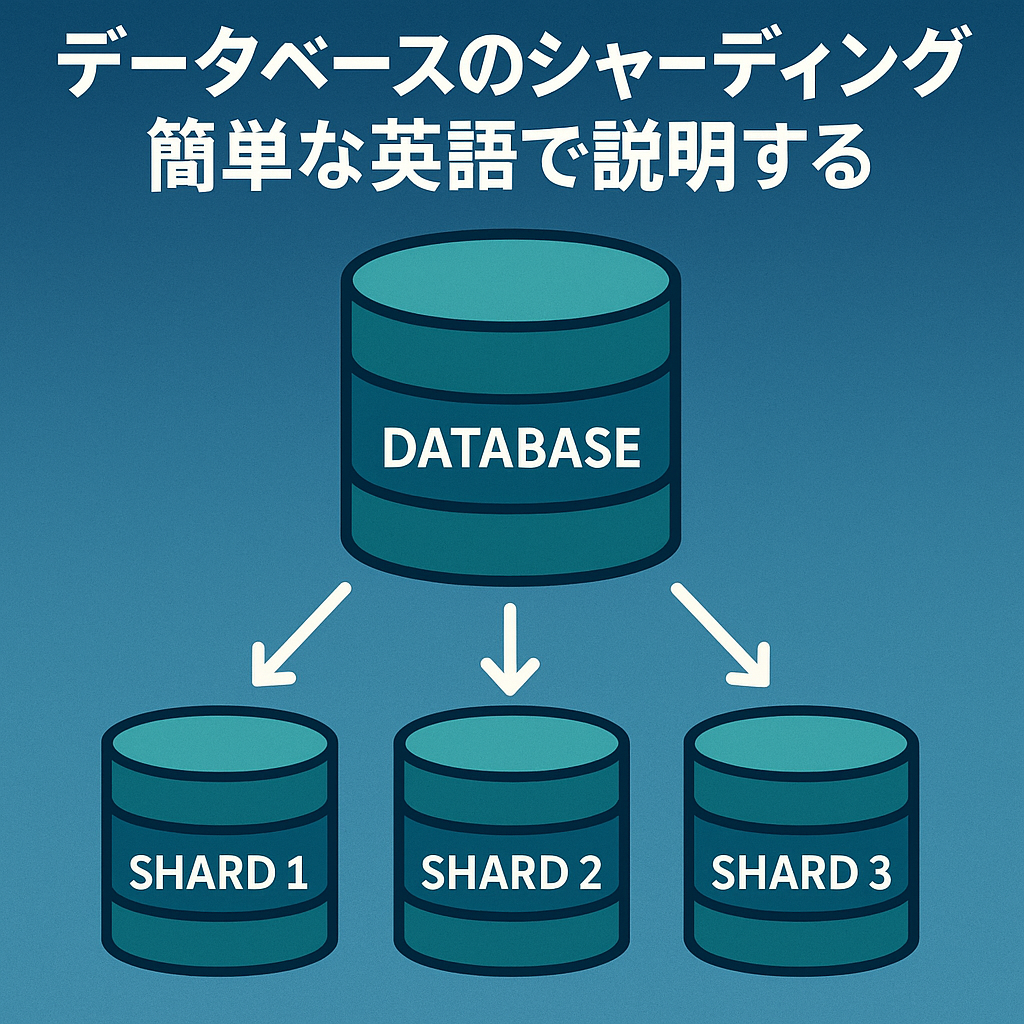
Database sharding explained in plain Englishの日本語訳。
シャーディングはほとんどの開発者にとって理解しにくいデータベースの話題の1つですが、シャーディングを自分自身で実装しない限り、必ずしも詳細が完全に明確になるものではありません。Citusデータベース(ベースであるデータベースをシャーディングするPostgreSQLの拡張機能)を構築する際、私たちはPostgreSQLを手動でシャーディングする場合と同じ多くの原則に従ってきました。Citusにおける主な違いは、Postgresをシャードし、それを簡単に使えるようにすることに多くの労力を払いましたが、アプリケーションレイヤーでシャードする場合は、アプリケーションを設計し直すために必要な作業がかなりあるということです。
筆者は、過去1年間に、シャーディングがどのように機能するかを多くの人に説明し(そしてたぶん面白い)、簡単な英語でシャーディングを詳細に説明するのが役立つだろうと気付きました。
パーティンションキーを定義する("シャードキー"あるいは"分散キー"とも呼ばれる)
中心部でのシャーディングは、データが小さなチャンクに存在する場所まで分割され、個別の入れ物に分散されます。ここでの入れ物は、テーブル、postgres スキーマ、または別の物理データベースです。スケーリングし続ける必要がある場合は、シャードを新しい物理ノードに移動してパフォーマンスを向上させることができます。
いずれのシャーディングの実装でも最初のステップは、データのシャードまたはパーティションの対象を決定することです。様々なキーに対するトレードオフが数多く存在し、いずれが正しいかはあなたのアプリケーションに依存します。何をシャードキーにするかを決定したら、シャードキーがアプリケーション全体に行き渡っているかを確認します(訳注:アプリのSQL文などがシャードキーを意識して書かれているかを確認する、といったこと)。これを行うにはいくつかの方法があります。簡単なものとしては、全てのモデルでシャードキーをマテリアライズすることです。マテリアライズ、または正規形を解除することで、アプリケーションでデータのルーティング方法を定義するクエリを少なくすることができます。
リクエストが来ると、アプリケーションレイヤーでシャーディングを行う場合は、アプリケーションはリクエストのルーティング方法を決定する必要があります(訳注:例としてはカスタマーIDでクエリを投げるデータベースを決定するようなルーティング)。同じ原則がCitusでも当てはまりますが、リクエストのルーティング方法を決定する余分な作業は必要ありません。シャードキーがクエリに含まれていれば、Citusはシャードキーを認識し、それに応じてクエリをルーティングします。
もう少し現実的な、Citusに送られたクエリの例を見てみましょう。この例ではCitusがどのようにクエリを書き換えるかが分かります:
SELECT *
FROM visits
WHERE occurred_at >= now() - '1 week'::interval
AND customer_id = 2上の例はCitusのルーター実行プログラムによって以下のように書き換えられます:
SELECT *
FROM visits_007
WHERE occurred_at >= now() - '1 week'::interval
AND customer_id = 2これで把握、つまり正しく理解できましたが?シャーディングについて必要なすべてが分かった...いえ、全然まだです。
シャードキーはシャード番号ではない
シャードキーに関するよくある誤解は、シャードキーを設定する際に、実際のシャードキーの値はルーティングを決定するメタデータのテーブルに存在する値だということです。実例、つまりSaaSアプリケーションの構築を見てみましょう。初年度から20人の顧客を獲得し、2年目には100、3年目には500人に増えたとします。あなたのSaaSアプリケーションはCRMシステムで、顧客毎にシャードすることを決めた理由は顧客のデータを他の顧客とは分離して保持する必要があるからです。早期に導入した顧客はより長期に渡ってアプリケーションを利用してきたため、1年目、2年目の顧客の方が3年目の新規顧客よりも多くのデータを保持している可能性があります。値をシャードにマップする方法を定義するオプションの1つは以下の通りです:
shard 1: customer ids 1-100
shard 2: customer ids 101-200
shard 3: customer ids 201-300
shard 4: customer ids 301-400
shard 5: customer ids 401-500
shard 6: customer ids 501-初期からの顧客は長期に渡ってより多くのデータを蓄積している可能性があるので、データ量の偏りが発生します。ID 1〜100(データをより多く持つ顧客)の顧客が同じシャードに置かれており、なぜこれが理想的でないかはすぐに分かるでしょう。
顧客でシャードすることには意味がある...でも何を?
顧客IDによるシャーディングは、特にマルチテナントのアプリケーションにおいては非常に一般的で、パフォーマンスとスケーラビリティの点で多くのメリットがあります。ただし上の例ではデータの分布が非常に不均一なシャードが発生し、シャード間でのデータの分散も不均一になる状況が示されています。この状況に対する解決策はどのようにシャードするかという実装にあります。筆者が言いたいのは、単なる「実装の詳細」です。少なくともこの場合、正しいとは言えません。
解決策はシンプルで、各customer_idをハッシュしてシャードに格納するハッシュ値をアップするテーブルを作成します。8つのシャードがあり、customer_idのハッシュを始めたとします。すると、Postgres内の整数のハッシュ値の範囲は、-2147483648 (-2^32) から 2147483647 (2^32-1) までとすることができます。そのハッシュ値の範囲を均等に分割すると、次の値を持つシャードが作成されます:
shardid | min hash value | max hash value
---------+----------------+----------------
1 | -2147483648 | -1610612737
2 | -1610612736 | -1073741825
3 | -1073741824 | -536870913
4 | -536870912 | -1
5 | 0 | 536870911
6 | 536870912 | 1073741823
7 | 1073741824 | 1610612735
8 | 1610612736 | 2147483647customer_idが入ってきたら、そのハッシュ値を評価します。顧客1の場合、私たちのハッシュは-1905060026に、顧客2は1134484726に、顧客3は-28094569になります。このとおり、1年目の早期の顧客がすでにシャード間で均等に分散し始めています。
シャードはノードではない
最初に簡単に述べたとおり、シャードはある種のデータの明確なグループです。シャードは物理インスタンスに関連付けられることがよくあります。実際は、基盤となっているインスタンスよりもシャードの数の方が多い場合に使用される多くの有効な方法があります。CitusのシャーディングではPostgresのテーブルがあり、少なくとも1つ以上、よくあるのはそれ以上、のシャードを含むノードを稼働させます。1つのノードに複数のシャードを配置することで、シャード内のデータを分割せずに、ノード間でシャードを移動して簡単にスケール出来ます。
8つのシャードを持つ上の例に戻りましょう。ノードが2つの場合を考えると、以下のようにマップされます:
shardid | min hash value | max hash value nodeid
---------+----------------+----------------+--------
1 | -2147483648 | -1610612737 | 1
2 | -1610612736 | -1073741825 | 2
3 | -1073741824 | -536870913 | 1
4 | -536870912 | -1 | 2
5 | 0 | 536870911 | 1
6 | 536870912 | 1073741823 | 2
7 | 1073741824 | 1610612735 | 1
8 | 1610612736 | 2147483647 | 2このセットをスケールアウトする場合、マッピングを変更せずに、半分のシャードを別のノードに簡単に移動できます:
shardid | min hash value | max hash value nodeid
---------+----------------+----------------+--------
1 | -2147483648 | -1610612737 | 1
2 | -1610612736 | -1073741825 | 2
3 | -1073741824 | -536870913 | 3
4 | -536870912 | -1 | 4
5 | 0 | 536870911 | 1
6 | 536870912 | 1073741823 | 2
7 | 1073741824 | 1610612735 | 3
8 | 1610612736 | 2147483647 | 4顧客ID vs エンティティID、同じアプローチを適用する
粒度の高いUUIDでシャーディングする場合であろうと、顧客IDのようなモデル階層の上位の何かでシャーディングする場合であっても、シャードキーを利用する前にハッシュするアプローチは変わりません。パーティションキーをハッシュし、どのようにルーティングされるかのマップを維持することは、スケーラブルなシャーディングアプローチの鍵です。Citusの中では、他の人が手動でシャーディングしてきた人が何年もやってきたことと同じ標準的な原則に従っています。中ではハッシュ値が入ってくると自動的にそれを評価し、カタログテーブル内でクエリを書き直すことなく、適切なテーブルまたはシャードへのルーティングが迅速に決定されます。
シャーディングがあなたにとって正しいか自信はありませんか?
シャーディングが全ての場合に意味があるとは限りませんが、データモデルが簡潔なシャーディングモデルに適合すれば、多くのメリットが得られる可能性があります。小規模なデータセットでもパフォーマンスの向上が得られ、さらに大事なこととして、いつどれほど大きくビジネスが成長するかという制約に出くわすことを心配する必要がなく、心配で夜も休めない、ということから解放されます。シャーディングが意味があるのかどうか質問がある場合は、気軽に連絡してください。