Azure StorageにアップロードされたCSVをAzure PostgreSQLに入れる
この記事は Azure Advent Calendar 2021 22 日目のエントリです。
何をするかというと
タイトルの通りなんだけども、AzureのStorage AccountのContainerにCSVファイルがアップロードされたら、Azure Database for PostgreSQL Flexible Serverに格納したい。
したいんだけども、それをPythonでやりたい、なぜならPythonが好きだから、というお話です。
実は以前にC#で書いたことがあって、その時は簡単に終わったんだけれども、同じことをPythonでやろうとしたら意外と苦戦したのに加え、ググってもほぼ見つからないのでこれは書いておいた方が良かんべぇ、という感じです。それにPythonなら、単に格納するだけじゃなく加工して格納するのも簡単に書けるしね。
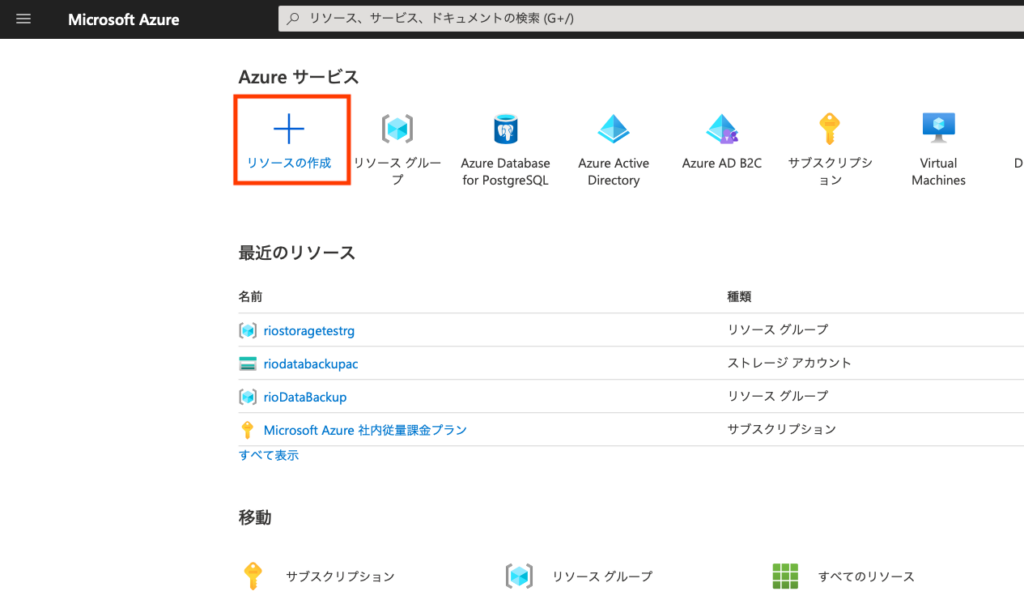
Storage Accountの作成
特に難しいことはないです。[リソースの追加]から
"Storage Account"を検索して
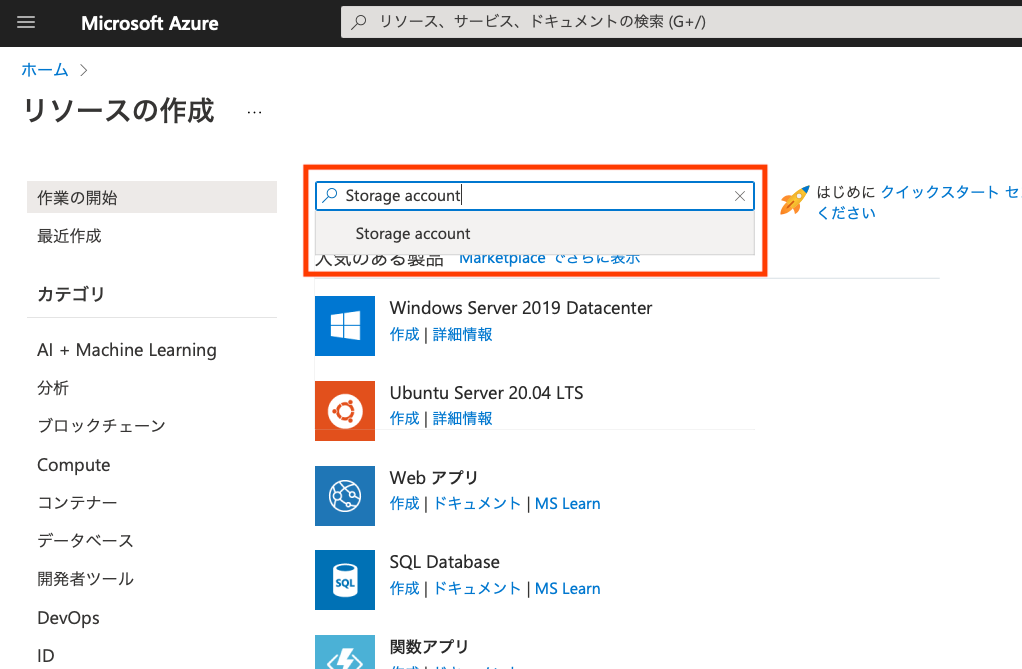
[作成]ボタンをクリックして
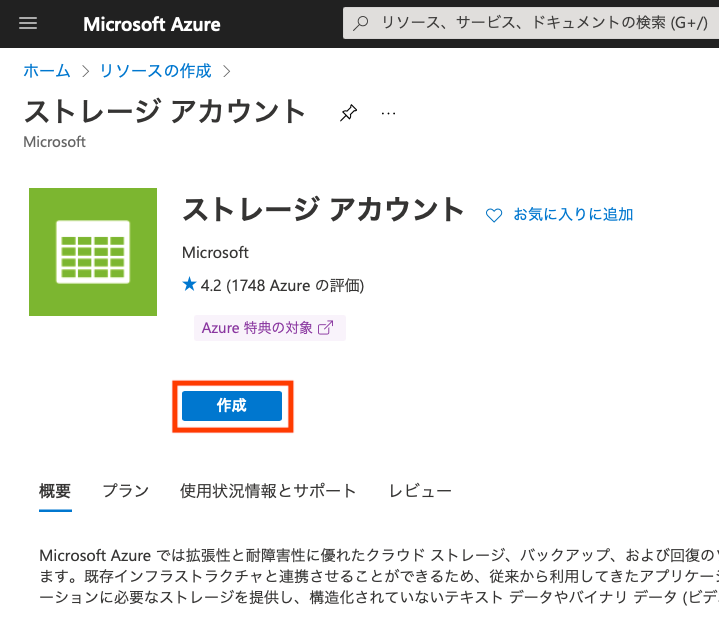
[リソースグループ]を新規に作成、[ストレージアカウント名]を入力して、[確認および作成]。
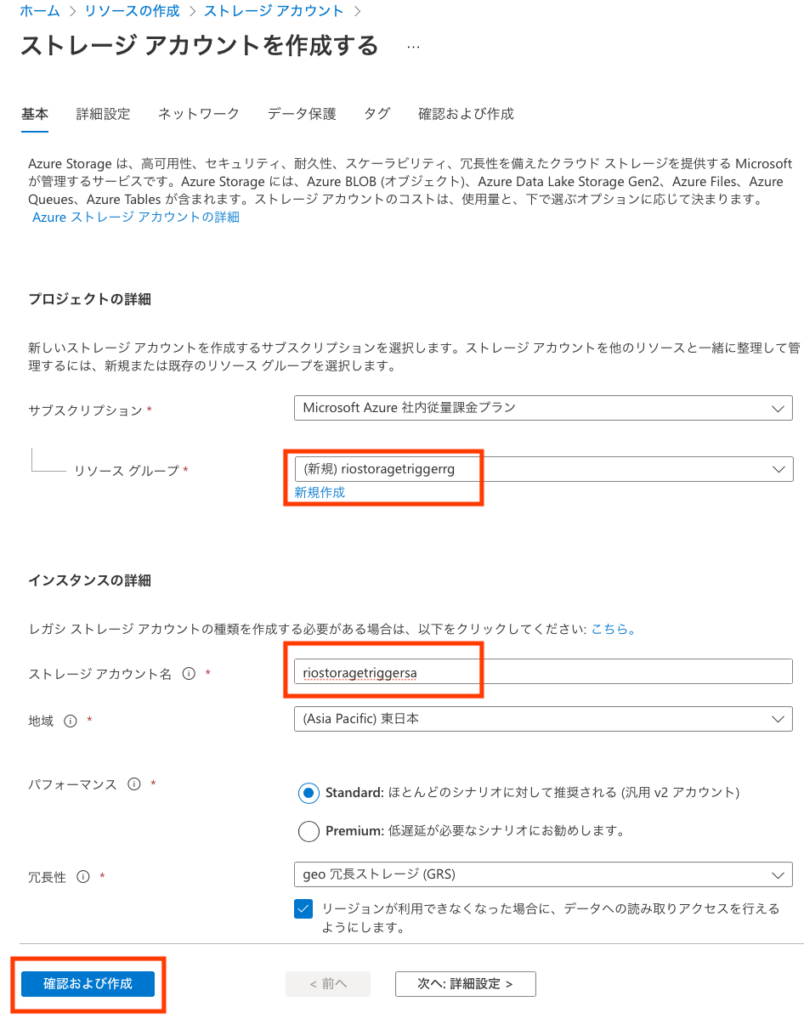
リソースのデプロイが完了したら移動して、ブレードから[コンテナー]→[+コンテナー]をクリックして
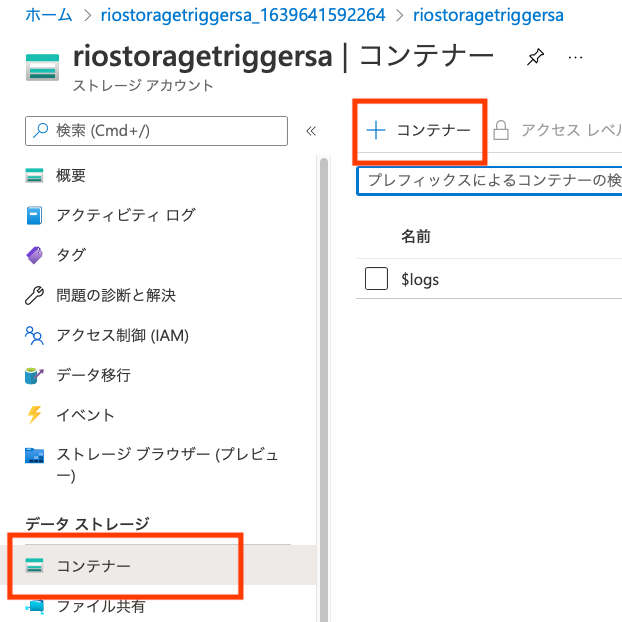
[名前]を入力したら[作成]ボタンをクリックすれば完了。今回は"csvstore"という名前に。この名前は後でAzure Functionで監視するコンテナーの名称として使うよ。
Visual Studio CodeでFunctionを作成
今回はPythonなのでAzure Portalから編集が出来るC#と違って、Visual Studio Codeで編集してデプロイすることになる。Azureのアイコンをクリックして、
Functionのアイコン(稲妻)をクリック、
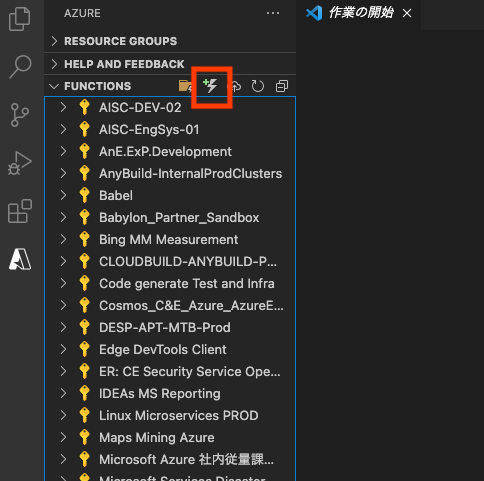
新規にプロジェクト作成を選ぶと、
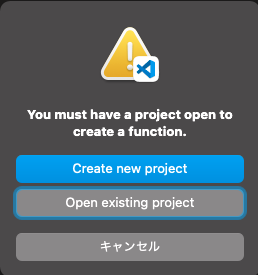
プログラミング言語を選択するリストから[Python]を選んで
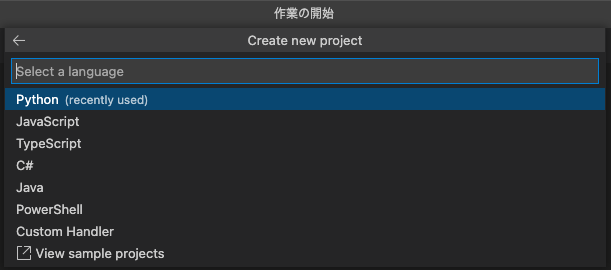
[python3 3.8.9]を選択
(ここ重要!)[Azure Blob Storage trigger]を選んで
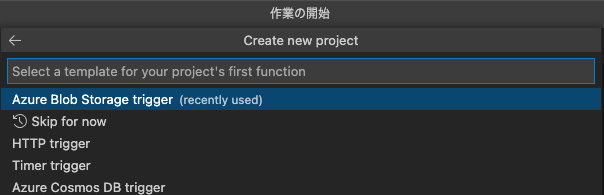
適当に関数名を入力して
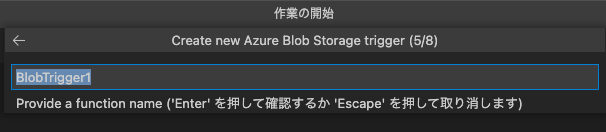
次に[+Create new local app setting]を選んで

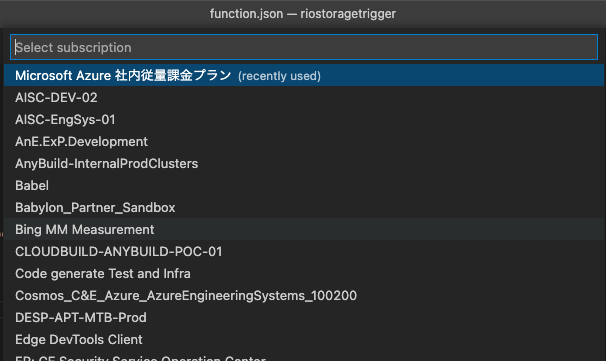
Functionを作成するサブスクリプションを選択
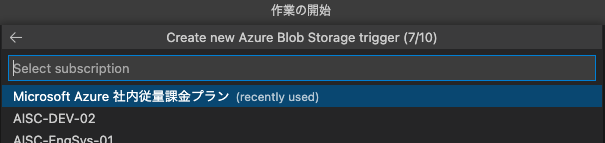
(ここ重要!)監視するストレージアカウントを選択して
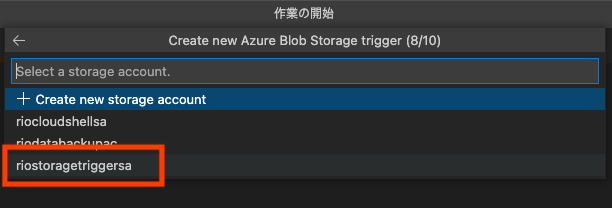
(ここ重要!)監視するパスを入力する、と。ここに先に作成したコンテナーの名称/{name}というパスを設定すると、そのコンテナーにファイルがアップロードされるとFunctionがトリガーされるようになる。
ファイルをアップロードしてもFunctionがトリガーされない時は、ここが正しいかをまず確認すること。
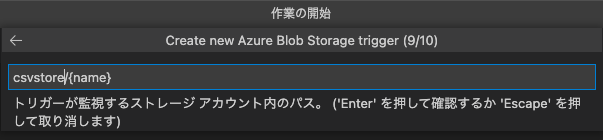
function.jsonの編集
上までの手順が完了するとPythonのプロジェクトのテンプレートが用意されるんだけど、さり気なく罠が仕掛けてある。
デフォルトの名称のままなら、"BlobTrigger1"フォルダの中にfunction.jsonが入っていて、その中の"connection"には"riostoragetriggersa_STORAGE"という値がセットされているけれど、これを"AzureWebJobsStorage"に書き換えて保存する。(ここ重要!)書き換えないとFunctionがトリガーされない。
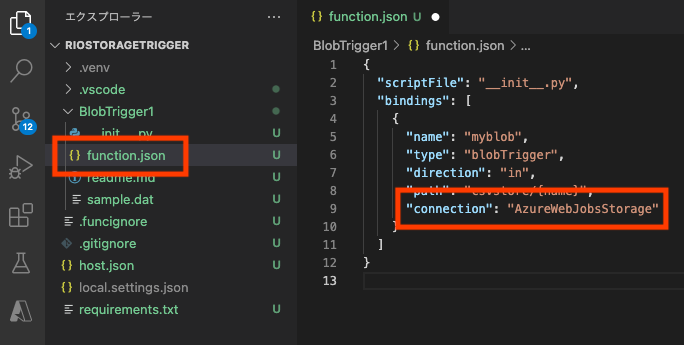
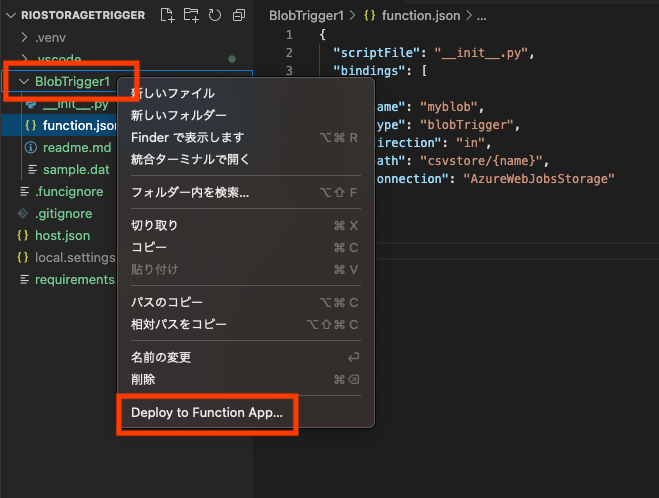
Functionのデプロイ
"BlobTrigger1"フォルダの名称を右クリックして、[Deploy to Function App...]をポイント
デプロイするサブスクリプションを選んでー
[+Create new Function App in Azure... Advanced]を選んで

Functionの名前を入力して
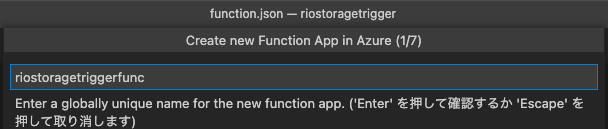
今回はプロジェクト作成の際に[Python3 3.8.9]を選択しているので、ここでは[Python 3.8]を選択
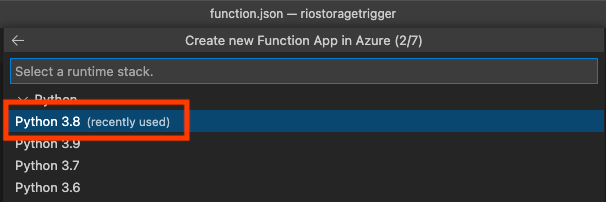
後でまとめて消せるようにストレージアカウントと同じリソースグループ([riostoragetriggerrg])を選択してるけど、もちろん新規に作成しても良い。
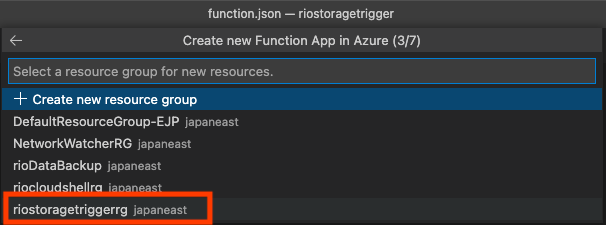
リージョン選んで
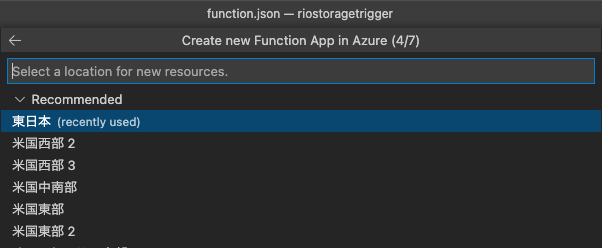
プランを選ぶ。今回はサーバレス(Consumption)を選んでるけど、アップロードの頻度が高い場合とかは、サーバレスだと処理が追い付かなくなることもあるので、本番はちゃんとテストしてくださいm(__)m
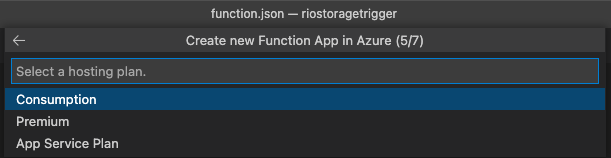
Functionのログとかを格納するストレージアカウントを選択するか、新規に作成して、
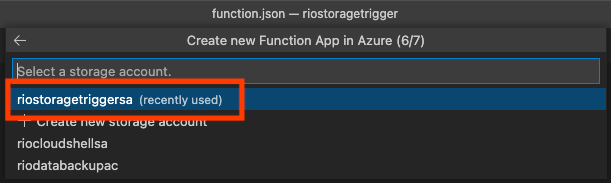
Application Insightsも作っちゃいます。じゃないとデバッグが辛くなるから...
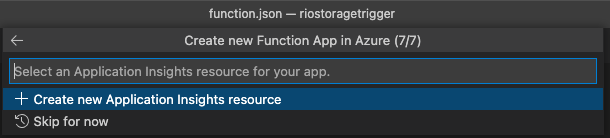
App Insightsの名前はデフォのままで
で、ここまでやるとデプロイが始まります。VS Codeの出力にデプロイのログが表示されるので、"Deployment successful."が出てくるまでコーヒーでも飲んでてください。
Functionの確認
ポータルに戻って、Functionを見つけます。ブレードから[関数]→[BlobTrigger1]をクリック
[モニター]を開いておきます。
ウェブブラウザのタブかウインドウをもう一つ開いて、ポータルからストレージアカウントを見つけます。ブレードから[コンテナー]→[csvstore]をクリック
コンテナーのウインドウで[アップロード]をクリック
適当なファイルを選んで[アップロード]します。
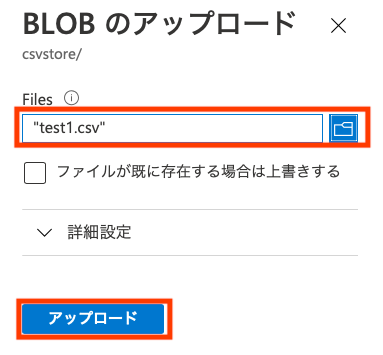
Functionの画面に戻って、しばらく待つとログあるいは[概要]の[成功した実行回数]にピョコンと変化があるはずです。
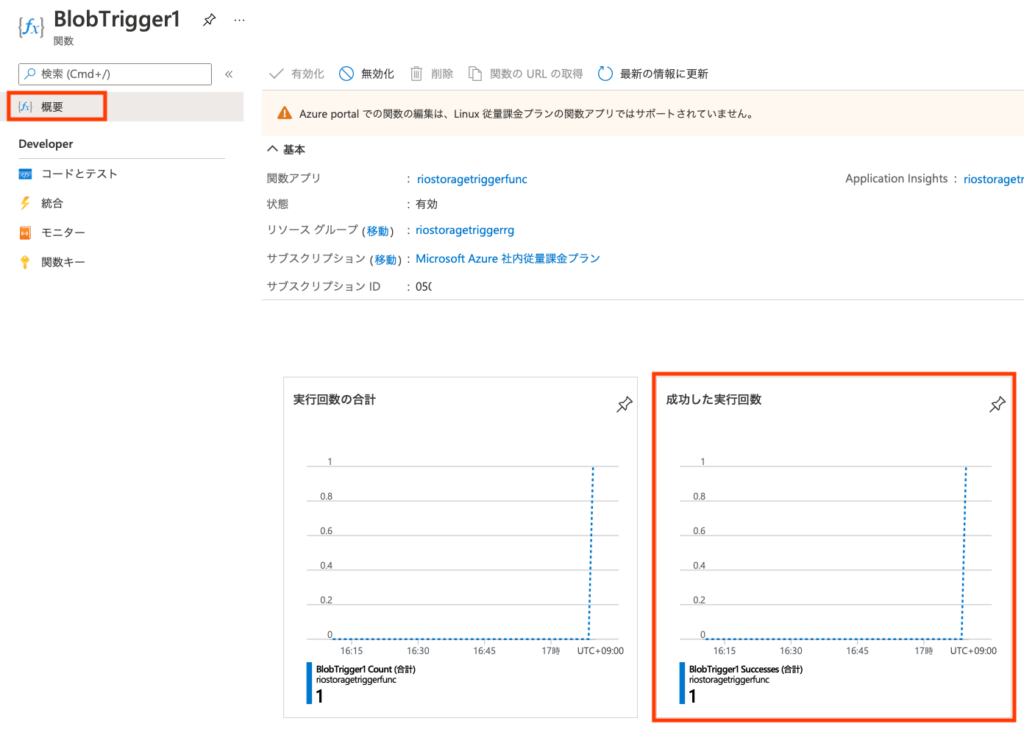
モニターの[呼び出し]→[呼び出しのトレース]にも表示が出ます。
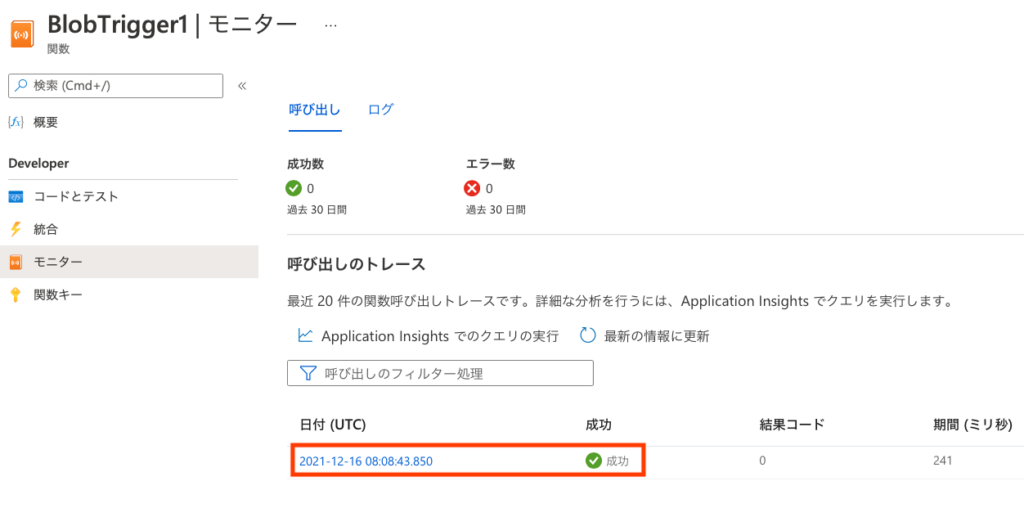
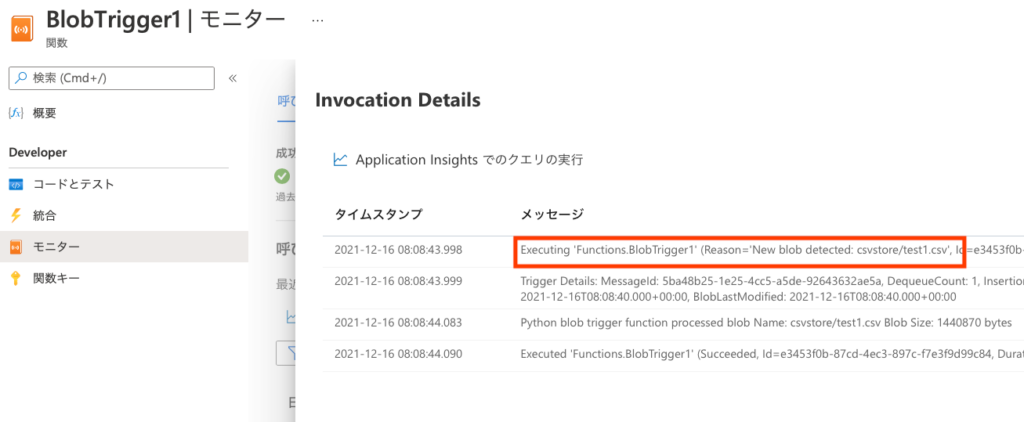
トレースから日時をクリックすると詳細が出ます。今のところ、Pythonでアップロードされたファイルの名称等をログ出力しているだけなので、コンテナーにアップロードしたファイル名がメッセージ中に表示されれば成功です。
で、ここまでやってFunctionがトリガーされない場合のポイントおさらい、
- function.jsonの"connection"に一字一句間違い無く"AzureWebJobsStorage"が設定されている
- function.jsonの"path"に、今回の例では"csvstore/{name}"、コンテナー名/{name}が設定されている
を確認し、もし間違えてないようならFunctionを一度再起動してみてください。
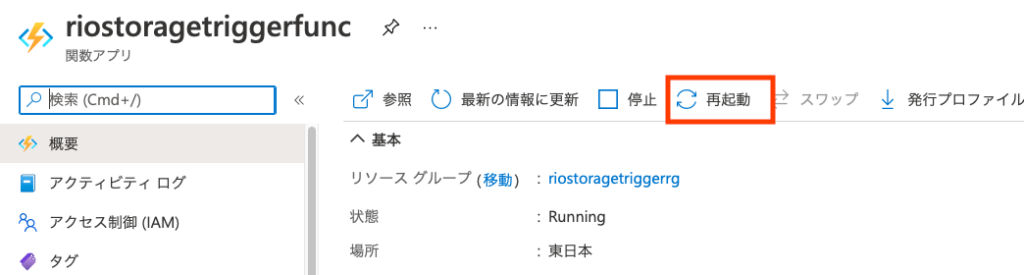
(ここ重要!)また、デプロイをし直した時も再起動しないと変更が反映されないことがあります。念の為再起動することで、古いコードのまま動作していて挙動が変わらず「あれ〜?」ってならないで済みます。
PostgreSQLをデプロイする
Azure CLIがあれば、一発です。途中、この作業をしている端末からのアクセスを許可するか確認されるので、接続出来るようにしておきます。
% az postgres flexible-server create -l japaneast
Creating Resource Group 'group3467360669'...
Detected current client IP : 59.138.207.68
Do you want to enable access to client 59.138.207.68 (y/n) (y/n): y
Creating PostgreSQL Server 'server687743184' in group 'group3467360669'...
Your server 'server687743184' is using sku 'Standard_D2s_v3' (Paid Tier). Please refer to https://aka.ms/postgres-pricing for pricing details
Configuring server firewall rule to accept connections from '59.138.207.68'...
Creating PostgreSQL database 'flexibleserverdb'...
Make a note of your password. If you forget, you would have to reset your password with "az postgres flexible-server update -n server687743184 -g group3467360669 -p <new-password>".
Try using 'az postgres flexible-server connect' command to test out connection.
{
"connectionString": "postgresql://rigidrelish8:M3_USqLup6N_ljduq70zRQ@server687743184.postgres.database.azure.com/postgres?sslmode=require",
"databaseName": "flexibleserverdb",
"firewallName": "FirewallIPAddress_2021-12-16_17-22-8",
"host": "server687743184.postgres.database.azure.com",
"id": "/subscriptions/050xxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/group3467360669/providers/Microsoft.DBforPostgreSQL/flexibleServers/server687743184",
"location": "Japan East",
"password": "M3_USqLup6N_ljduq70zRQ",
"resourceGroup": "group3467360669",
"skuname": "Standard_D2s_v3",
"username": "rigidrelish8",
"version": "12"
}Connection Stringをコピーしてテーブルを作っておきます。
% psql "postgresql://rigidrelish8:M3_USqLup6N_ljduq70zRQ@server687743184.postgres.database.azure.com/postgres?sslmode=require"
-c 'CREATE TABLE users (
id BIGSERIAL,
username TEXT,
name TEXT,
sex VARCHAR(1),
address TEXT,
email TEXT,
birthdate DATE);'
CREATE TABLE(ここ重要!)もう一点、ネットワーク接続については先に作成したFunctionからPostgreSQLへの接続が許可されている必要があるので、作成し終わった後にPostgreSQLの[ネットワーク]で設定しておきます(createコマンド実行時に"--public-access 0.0.0.0"を付与しても可)。
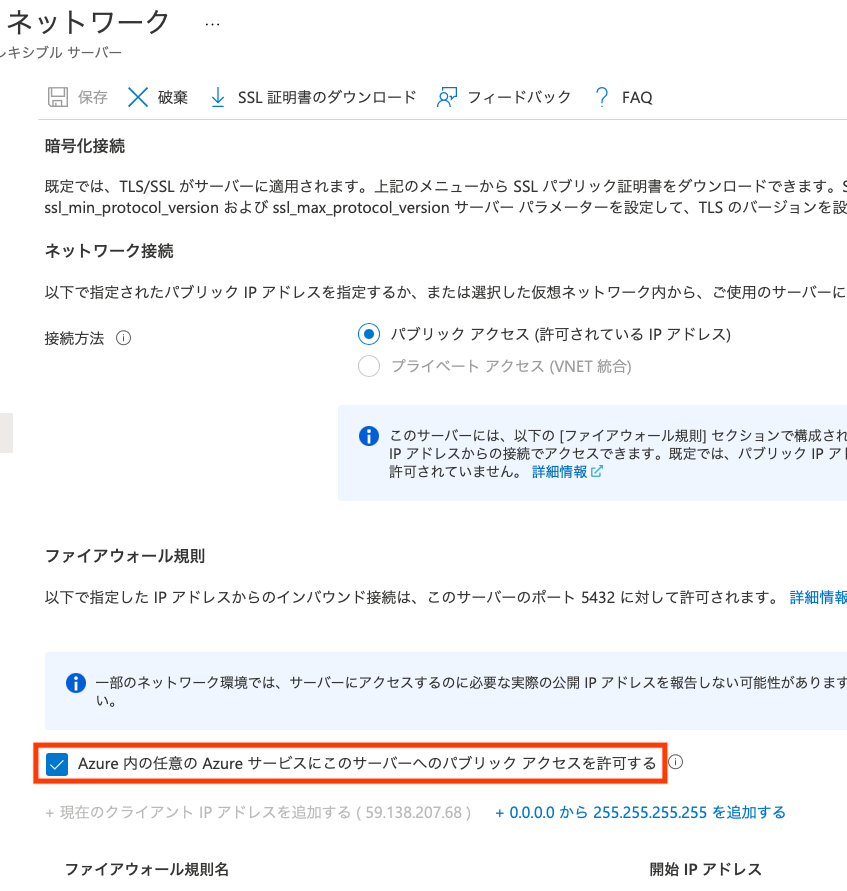
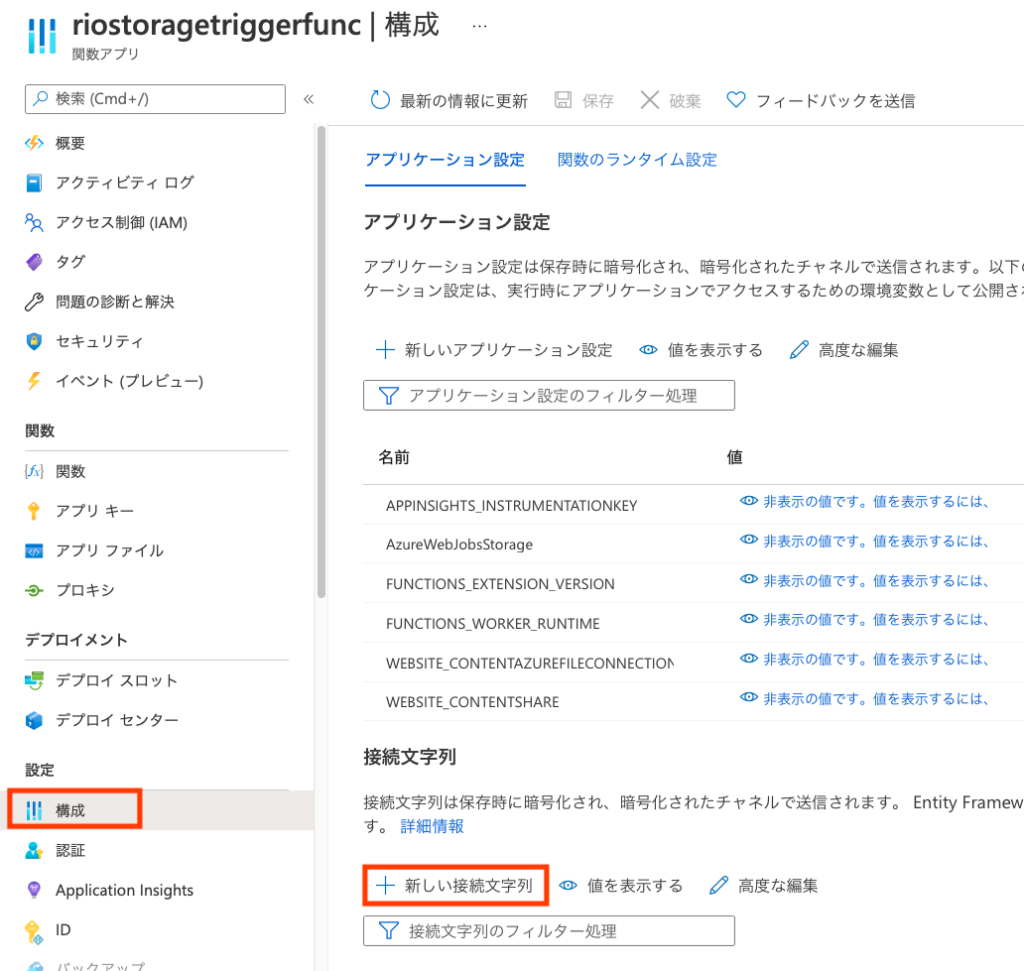
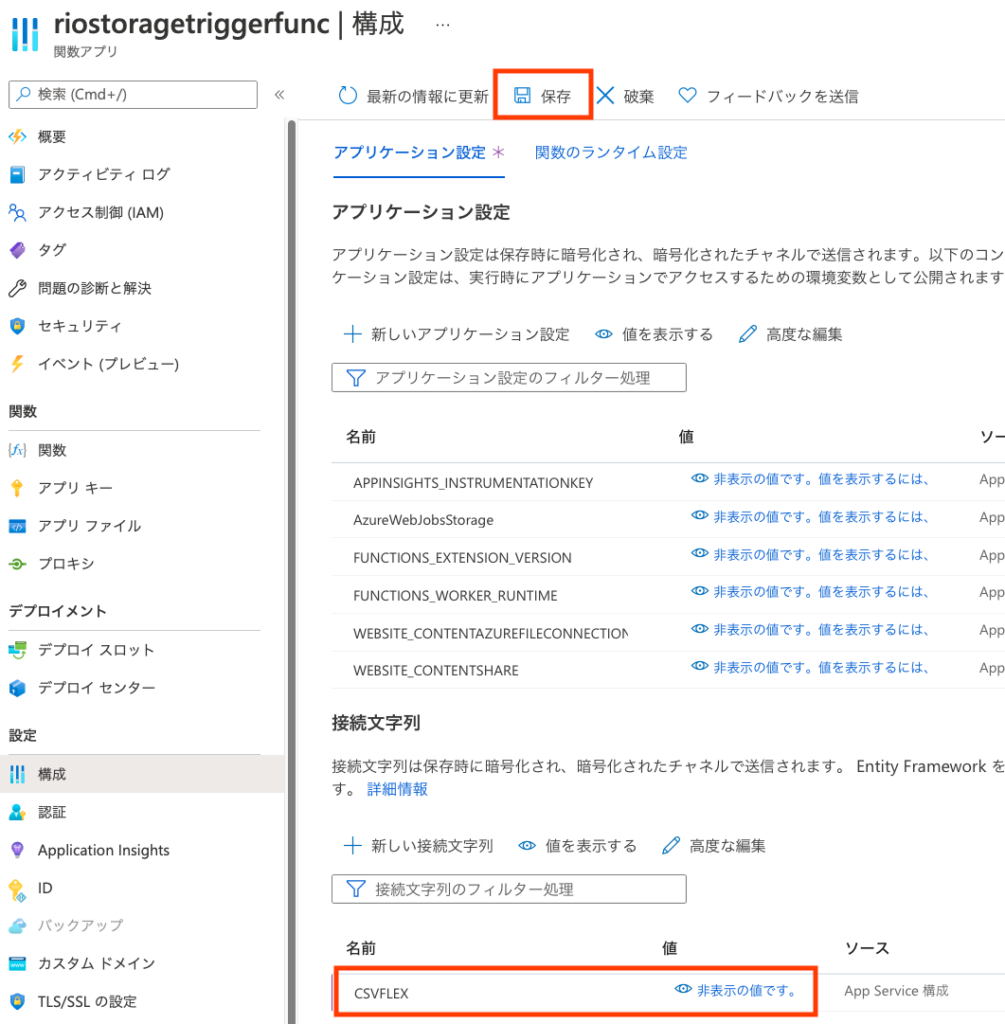
Functionに接続文字列を設定する
Functionの[構成]をクリックして、[+新しい接続文字列]をクリック
[名前]に"CSVFLEX"、[種類]を"PostgreSQL"にして、[値]を先のflexible-server createコマンドの結果を加工して以下のようにします。
host=server687743184.postgres.database.azure.com port=5432 dbname=postgres user=rigidrelish8 password=M3_USqLup6N_ljduq70zRQ sslmode=require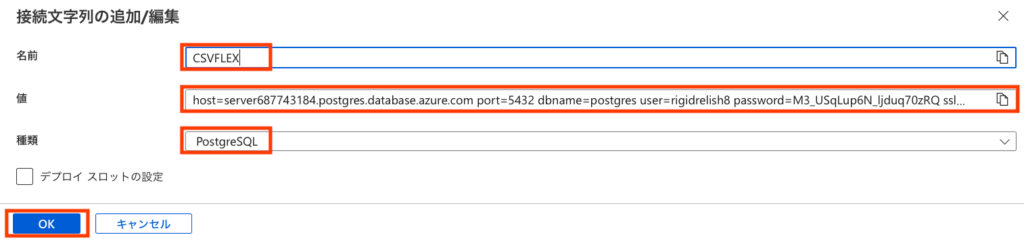
値が追加されたことを確認して、[保存]
コードを修正
VS Codeに戻って、requirements.txtを以下のように編集し、保存します(ここ重要!)。
# DO NOT include azure-functions-worker in this file
# The Python Worker is managed by Azure Functions platform
# Manually managing azure-functions-worker may cause unexpected issues
azure-functions
psycopg2-binary==2.9.2Pythonのコードでimportしているのはpsycopg2ですが、Function Runtime環境にはlibpqがインストールされていないため、NotFound怒られが発生します。なので、
% pip install psycopg2-binaryさせるようにします。
次に、__init__.pyを以下のように編集し、保存、Functionを再デプロイします。再デプロイした後、Functionの再起動を忘れずに。
import csv
import logging
import os
import azure.functions as func
import psycopg2
from psycopg2.extras import execute_values
def main(myblob: func.InputStream):
with psycopg2.connect(os.getenv('POSTGRESQLCONNSTR_CSVFLEX')) as con:
with con.cursor() as cur:
input_text = myblob.read(size=-1).decode('utf-8')
reader = csv.reader(input_text.splitlines(), quoting=csv.QUOTE_ALL)
params = []
for row in reader:
params.append(tuple(row))
query = "INSERT INTO users (id, username, name, sex, address, email, birthdate) VALUES %s"
ret = execute_values(cur, query, params)
con.commit()上でFunctionに設定して接続文字列は、POSTGRESQLCONNSTR_ポータルで入力した名称、の環境変数になるので、os.getenv()がos.environ()で取得出来ます。
func.InputStream.read(size=-1)で(もしくはsize=None)EOFまでファイルの中身を読んじゃってるので、あまり大きなファイルだとメモリ不足になるかもしれませんが、ここではヨシ!としておきます。
あと、本当にInputStreamはCSVなのかとか、これはこのテーブルに格納するCSVなのかとかエラーハンドリングは色々すべきですが、そこは頑張って仕様を決めて実装してください(笑
ダミーデータを生成する
ま、こんな感じに。上のCREATE TABLE文に合わせたダミーデータです。面倒な人はダウンロードしてください。
#!/usr/bin/env python3
from faker import Faker
import csv
import random
fake = Faker('ja_JP')
with open('./dummy_data.csv', 'w') as f:
res = [[i, fake.user_name(), fake.name(), random.choice(['M', 'F', 'N']), fake.address(), fake.email(), fake.date_of_birth()] for i in range(1, 10001)]
writer = csv.writer(f, quoting=csv.QUOTE_ALL)
writer.writerows(res)データをアップロードする
はい、いよいよPostgreSQLにINSERTされるかどうか分かりますね。csvstoreコンテナに、ダミーデータのファイルをアップロードしてみましょう。
で、PostgreSQLにpsqlで接続してっと、

はい、無事に格納できました。
まとめ
え、こんなことしなくても、Azure Data Factoryがあるじゃん!って思った方、正解ですw
正解なんだけど、コードが書けるならこっちの方が自由度が高くて良いでしょ、ということで書いてみました。