Azure HPC VMでStable Diffusionすると速いのか?(結論:すげえ速かった)

手元にあるSDできる環境はMac Studioのみなのだけど、GPUとして見た時にはMac Studioの性能はRTX3090の半分以下のようなので、もうちょっと速い環境が欲しいっちゃ欲しい。メモリ24GBを搭載しているRTX4090は確実に3090より速いわけだが、執筆時点で約30万円。うーん、ゲームをプレイするにしてもこいつはあまりコスパが良くないなということで、AzureのHPC用のVMでSDを動かしてみた。
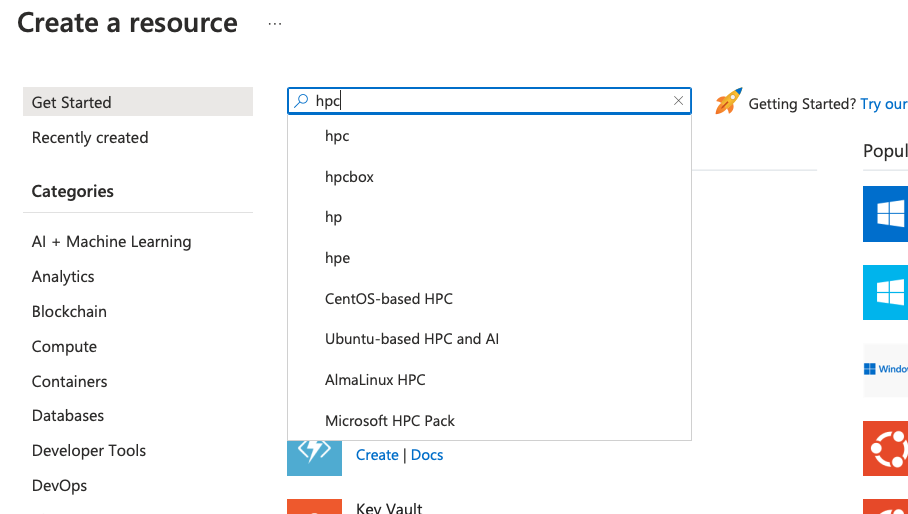
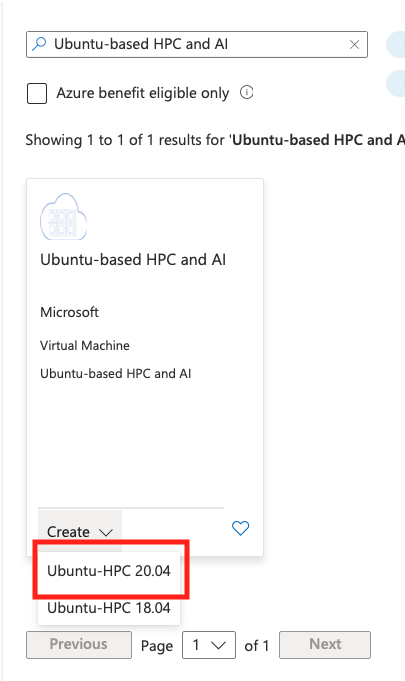
どのVMを使うか
Azure VMでGPUが使えるシリーズはいくつもあるけれど、VDIがしたいわけではないし、そんなにデカいインスタンスを使ったところでStable Diffusionが生成できる画像のサイズには限度があるので、NVIDIAのA100が使えるNC_A100_v4シリーズから選択。
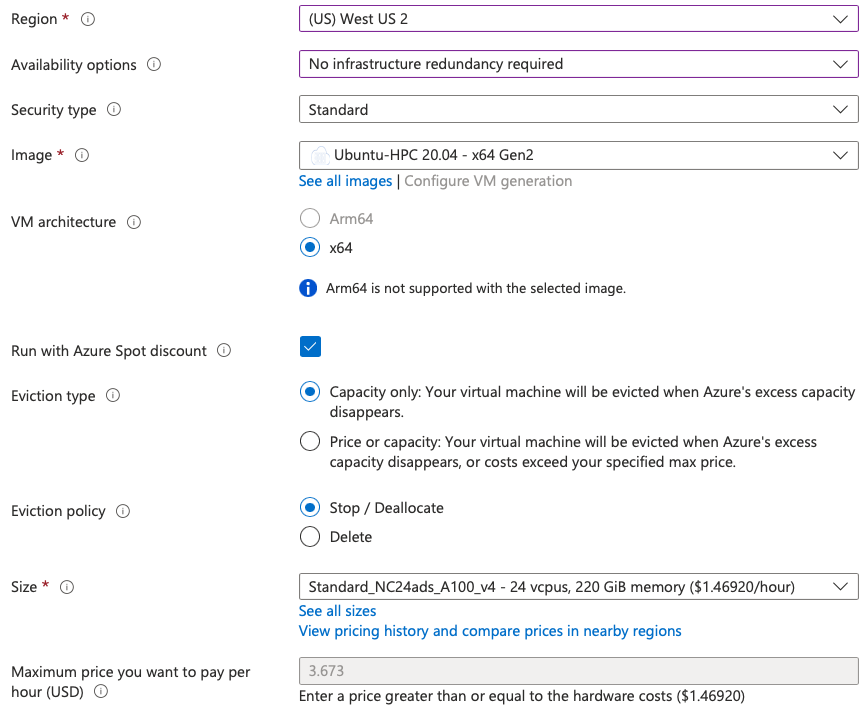
電気代とか諸費用の関係でリージョンによって結構お値段は異なるので、執筆時点で出来るだけ安いところということでWest US 2にStandard_NC24ads_A100_v4を。500円/時間で80GBのGPUメモリが搭載されたA100付きのVMを「継続して」使えるのだけど、もうホント1時間だけ安く使いたい、という使い方なんでスポットインスタンスにして節約しましょう。同じWest US 2でスポットインスタンスだと、$1.4692/hour、ちょうど200円/時間ぐらいでイケそうです。ただしこれはデータディスクを付けない場合の料金なので、注意が必要。OSディスクが30GBなので、これを64GBにして生成された画像もそこに置いておく...の方がお安いと思われ。ディスクの容量はむしろ、モデルやLoRAをいくつ使いたいかに依るので、そこはよしなに。
くれぐれもビックリするような請求をされないように気を付けて楽しもう。
VMをデプロイする
AzureポータルからUbuntuベースのHPC VMをデプロイ。

[Availability options]は冗長化無し、で[Run with Azure Spot discount]を選ぶと自動的に[Size]が"Standard_NC24ads_A100_v4"になるはず。
データディスクを付ける場合は、"Create and attach a new disk"から、
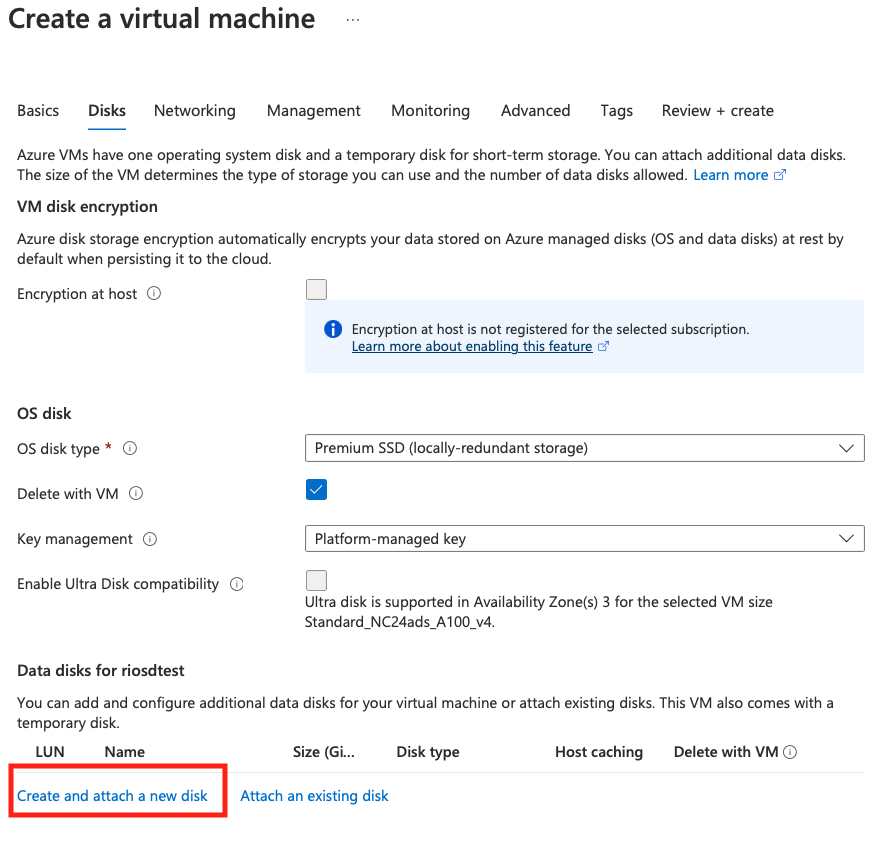
1TBもたぶん要らないかと。
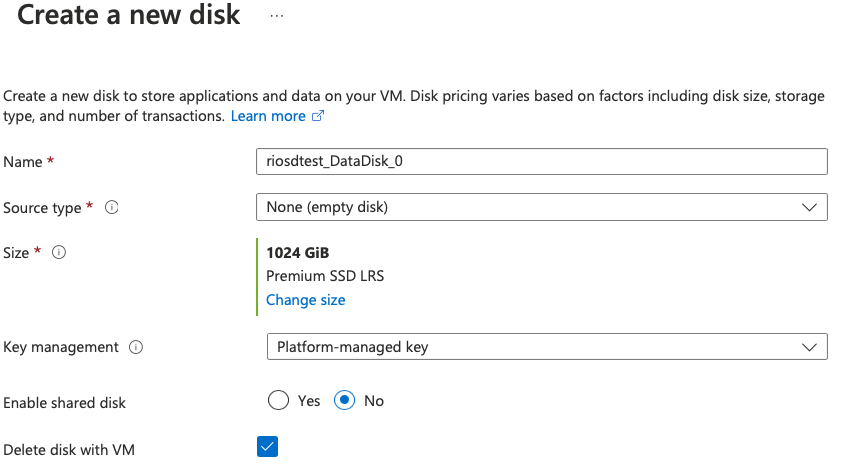
あと、[Management]の[Auto-shutdown]を設定しておくと、クラウド破産しなくて済みます。あとは[Create]をクリックすればデプロイできます。
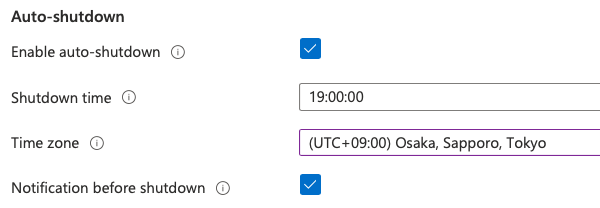
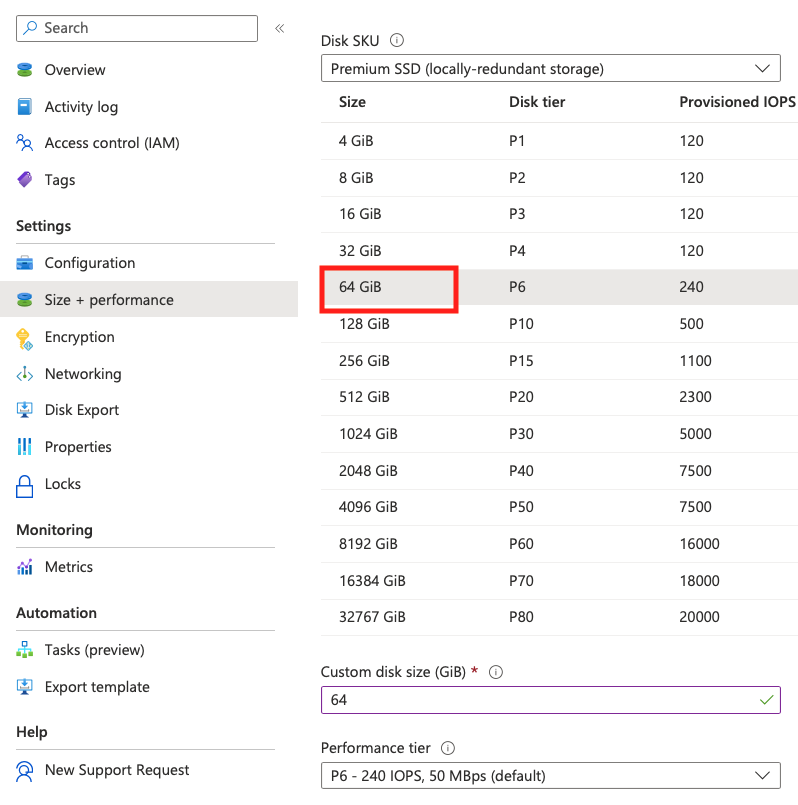
OSディスクを拡張する場合は、デプロイ完了後に一度VMを停止(Deallocate)してから、[Disks]からOSディスクを選択し、
64GBとかに。OSディスクは拡張すると自動的にファイルシステムも拡張されるので、データディスクを拡張するより楽ちんかも。
AUTOMATIC1111をどこにインストールするか
OSディスクの拡張ではなくデータディスクをアタッチした場合、ざっくり以下の手順が必要。
- sudo fdisk -lでデータディスクを確認。
- sudo fdisk /dev/sdcでパーティションを作成(1でsdcだった場合)。
- sudo mkfs.xfs /dev/sdc1
- sudo blkid /dev/sdc1して、/etc/fstabに
UUID=xxxxx-xxxx... /opt/sd xfs defaults,discard 0 0
とか追加。 - sudo mkdir /opt/sd
- sudo mount /opt/sd
- sudo chown user.user /opt/sd
で、この/opt/sdにAUTOMATIC1111をcloneする感じ。OSディスク拡張なら、ユーザホームディレクトリの容量に余裕があるはずなので、そのまま~/sdとか作っても良し。
AUTOMATIC1111をインストールする
Bastionかsshでログインする
セキュリティ的にはBastionがオススメなんだけど、作業内容によってはBastionだと難しいこともあるので、その時だけsshを開けるのが良いかと。sshは時限で自動的に塞がれます。
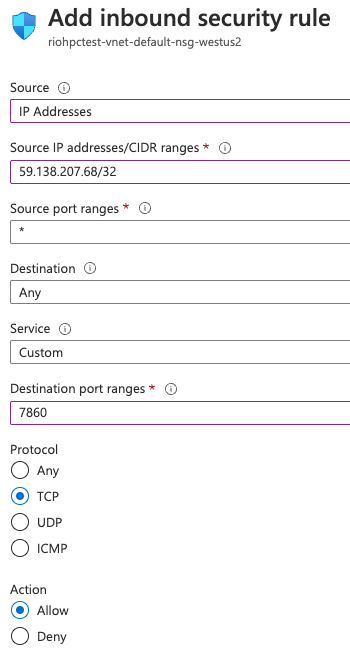
sshも、Stable DiffusionのWeb UI(AUTOMATIC1111のtcp/7860)へのアクセスも、NSG(Network Security Group)でアクセス元IPアドレスを制限しておくこと。じゃないと、勝手に使われたりしちゃうので。
あと、MacでBastionを使う場合、Safariだとペーストが出来ないので、Edge / Chrome推奨。
以下、~/sdにインストールするものとして、適宜読み替えてください。
Python venv入れる
これが無いとAUTOMATIC1111が動かん。Ubuntu20.04なんで、Python 3.8で行きます。
$ sudo apt-get update
$ sudo apt-get -y install python3.8-venvAUTOMATIC1111をclone
$ cd ~/sd
$ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webuiwebui-user.shを編集
$ cd stable-diffusion-webui
$ vim webui-user.shコマンドラインの引数がコメントアウトされているので、
#export COMMANDLINE_ARGS=""以下のように変更。その他の引数についてはドキュメント参照。
export COMMANDLINE_ARGS="--listen --enable-insecure-extension-access --xformers --no-half-vae"AUTOMATIC1111を起動
$ ./webui.shすると、URLが表示される。
Model loaded in 1.6s (create model: 0.3s, apply weights to model: 0.3s, apply half(): 0.1s, load VAE: 0.6s, move model to device: 0.2s).
Running on local URL: http://0.0.0.0:7860NSGの設定
上記URLにアクセスするには、Azure VMのtcp/7860がオープンになってないとならない。VMの[Network]→[Add inbound port rule]で以下。ソースIPは制限。
ブラウザでアクセスしてみる
AUTOMATIC1111の設定
Extensions、VAE、Model / LoRA等をインストールする。
Extensions
Install from URLから特に問題なくインストール可能。
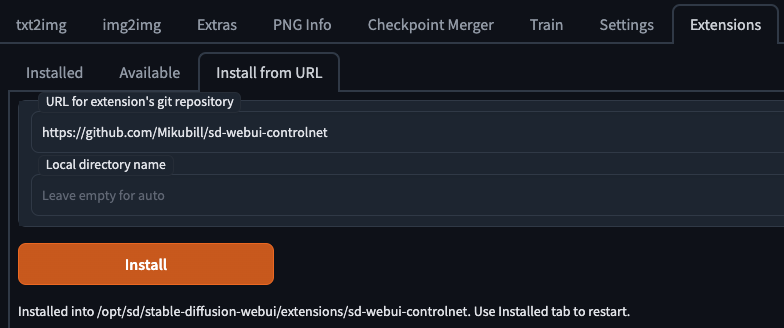
Openpose Editor: https://github.com/fkunn1326/openpose-editor
WebUI Controlnet: https://github.com/Mikubill/sd-webui-controlnet
VAE
例えば、Hugging Faceからなら、
$ cd ~/sd/stable-diffusion-webui/models/VAE
$ wget https://huggingface.co/AIARTCHAN/aichan_blend/resolve/main/vae/Anything-V3.0.vae.safetensorsで、有効にして再起動。
Model / LoRA
例えば、CivitaiからRealDosMixなら、
$ cd ~/sd/stable-diffusion-webui/models/Stable-diffusions/
$ curl -LOJ https://civitai.com/api/download/models/8137同様にLoRA(2B (NieR:Automata) LoRA / YorHA edition)なら、
$ cd ~/sd/stable-diffusion-webui/models/Lora/
$ curl -LOJ https://civitai.com/api/download/models/6031Embedding
EasyNegativeなら、
$ cd ~/sd/stable-diffusion-webui/embeddings/
$ curl -LOJ https://civitai.com/api/download/models/9208ControlNet
ControlNetのモデルはHugging Faceにあるので、openposeなら、
$ cd ~/sd/stable-diffusion-webui/models/ControlNet/
$ curl -LOJ https://huggingface.co/webui/ControlNet-modules-safetensors/res
olve/main/control_openpose-fp16.safetensorsやってみよう
以下の画像をMac Studioで描かせると、7分55秒かかった。

Azure VMだと同じシードでもかなり違う絵が出てくるが、なんと16秒しかかからない!

約30倍も速い!
同じ時間で、違うシード値を30回試せるということだ。え、どういうこと、なんでそんなに速いん?
Hires. fixで2880 x 1440
さらにAzure VMで試しにHires. fixで2倍、つまり2880 x 1440を描かせてみたところ2分54秒だった。ただし、WebUIからファイルがダウンロードできなかったので、Azure VMから自宅鯖にscpで転送した。転送サイズの制限か何かかな?

2048 x 1024 + Hires. fix
ん?ひょっとしてもっとデカいの描ける?Web UIで2048ピクセルまで設定出来るので、2048 x 1024に設定してHires. fixしてみる。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 72.00 GiB (GPU 0; 79.17 GiB total capacity; 22.36 GiB already allocated; 48.94 GiB free; 28.66 GiB reserved in total by PyT
orch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF落ちたwww
メモリが足らん。Standard_NC48ads_A100_v4にすればたぶんイケる。
結論
200万円を超えるGPUは速い(速い)。でもスペックを見ると消費電力は300Wなのね...。

これを、時間あたり数百円で使えるクラウドってやっぱりスゴイね...。そして恐ろしいことに、今回試したのはA100が1枚のみのStandard_NC24ads_A100_v4。料金が4倍になるが、Standard_NC96ads_A100_v4では、このGPUが4枚使える...。グラボだけで900万円の構成です。対戦ありがとうございました。
作業が終わったらVMを停止するのを忘れないように!