PostgreSQLに20TB・89億件のデータを入れてみる
そーだいさんがこんなことを呟いていた。
ふーむ。これはやってみないといけないですね。
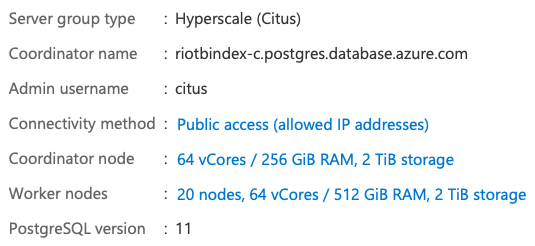
普通のPostgreSQLではちょっと無理っぽい件数なので、Azure Database for PostgreSQL Hyperscale (Citus)に入れてみる。海外さんのPGstromという変態実装(褒めている)を使う方法もあるけれど、PaaSでRDBMSで、っていうとHyperscale (Citus)がまず候補かな、と。
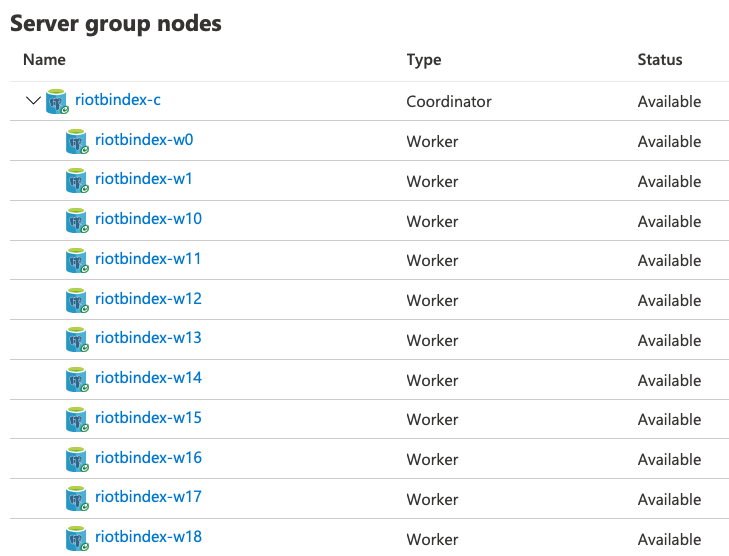
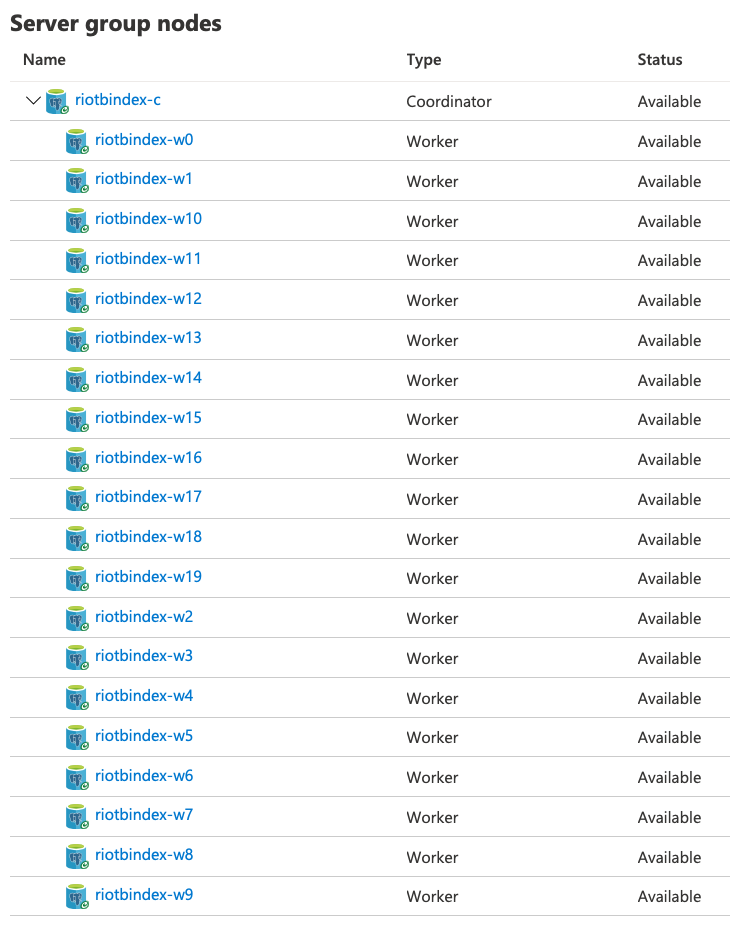
ちょっとどんな感じか分からないので、IOPSが最大になる2TBのストレージを持つワーカーノードを20台で構成してみる。
全体としてはこんな感じ。
で、64vCPUのVMにPremium SSDのData Diskを付けたUbuntuにpostgresql-clientをインストールした上で20TBのCSVデータを用意。splitコマンドで適当なサイズに分割して、
$ find chunks/ -type f |
xargs -n1 -P64 sh \
-c "psql -h riotbindex-c.postgres.database.azure.com -p 5432 -d citus --username=citus \
-c \"\\copy table1 from '\$0' WITH CSV\""って感じに投入する。クライアントを64vCPUにしたのはpsqlを64並列でデータ投入するから。コーディネータノードも64vCPUなので良いだろうと思ったら、もう少しコーディネータには余裕があった。
投入するのに、約7時間かかった...。さて、入ってるかな?
citus=> \timing
Timing is on.
citus=> select count(*) from table1;
count
------------
8887648000
(1 row)
Time: 7689798.324 ms (02:08:09.798)デフォルトパラメータのままだと、89億件を数えるのに2時間かかる...。
さて、本筋はインデックスですね、やってみましょうこうですか分かりません。
psql > CREATE INDEX table1_index ON table1 (ev_type);
CREATE INDEX
Time: 4884228.616 ms (01:21:24.229)というわけで、1時間21分24秒でした。

