はじめに
Cosmos DB for NoSQLのオススメ言語はC# / Node.jsなのだけれど、AIや他のソリューションと組み合わせる時にPythonの膨大な資産はやはり魅力的なこともあり、Azure FunctionsをPythonで書いてCosmos DB for NoSQL、あるいは他のAPI(MongoDB, Apache Cassandra, Apache Gremlin, Table)に接続し、ChangeFeedを使ってフレキシブルかつスケーラブルなアプリを実装したいというニーズは、ちょっとはあるんじゃないかと思い、ここにまとめることにした。というか自分の備忘録でもあるため、気付いたことは後日追加していこうと思うのでトップページに固定しておく。
疑問に思ったら公式ドキュメントにあたること。
制約
Cosmos DBに接続する際のプライマリーの言語はC# / Node.jsなので、Pythonだといくつか制約があることは事前に了承のこと。例えば、執筆時点(2023.07.28)では階層型パーティションキー(Hierarchical Partition)はPythonでは利用出来ない、といった類いのものだ。Cosmos DBの最新の機能への対応は、プライマリー言語から先行して行われるのが主たる理由なのだけれど、Cosmos DBもそこそこ歴史があり(ベースとなるBW-Treeの論文は2013年)、利用実績も十分にあるので、Pythonで利用出来る機能だけでもそれほど困ることは無いとも思われる。
基本的な考え方
密結合ではなく疎結合
Pythonに限らずどの言語で開発する場合でも、Cosmos DBのようなNoSQLを使ったアプリケーションは原則として疎結合であるべきだ。RDBMSのようなACID特性を持たないことやスケーラビリティを考慮し、可用性(Availability)ではなく回復性(Resiliency)をより重視すれば当然の帰結ではあるのだけれど、この基本原則が理解されてないパターンを散見するので敢えて書いておく。
Cosmos DBは”DB”じゃない
RDBMSのことは一旦忘れよう。Cosmos DBはRDBMS文脈で言うところのDBではない。ACID特性は無いし、クエリーもSQL「ライク」でしか無いし、トランザクションも無い(Cosmos DB側で設定可能だが、利用することは稀)。絶対にダメなのは、RDBMSのデータモデルやRDBMSに依存した実装のアプリケーションをCosmos DBにそのまま持ってくることだ。
じゃあメリットは何なのかというと、上で書いた「無い」ものを捨てた代わりに得られる、スケーラビリティや非常に高い書き込み性能、あるいはグローバルマルチマスターといった機能だ。
スケーラビリティについては、以下の事例を見れば説明は要らないだろう。
- TeamsのデータストアはCosmos DB、1日にストアされるメッセージは数兆に及ぶ
- OpenAI社のChatGPTのデータストアもCosmos DB、こちらもメッセージ量など説明の必要は無いだろう
NoSQL APIの場合、書き込み及び読み出し性能は1KBのドキュメントであれば、10ms未満をSLAで保証している。平均値は2,3msほど。この書き込み性能を保証しているのは、上述のBW-Treeによるハードウェアレベルで最適化されたバックエンドの実装だ。
グローバルマルチマスターは、Azureのどのリージョンでも書き込めて、読み出せる機能。例えば、Teamsで日米でチャットしている時、チャットデータはネットワークを経由してお互いのTeamsアプリに「飛んで」いるわけではない。日本で書き込んだ場合、Azure東日本か西日本にあるCosmos DBに書き込まれ、それがUSのいずれかのリージョンのCosmos DBに同期され、US側のTeamsアプリが読み出している。この際、ユーザーが全世界に散らばっていても、直近のリージョンのCosmos DBに読み書きしている。
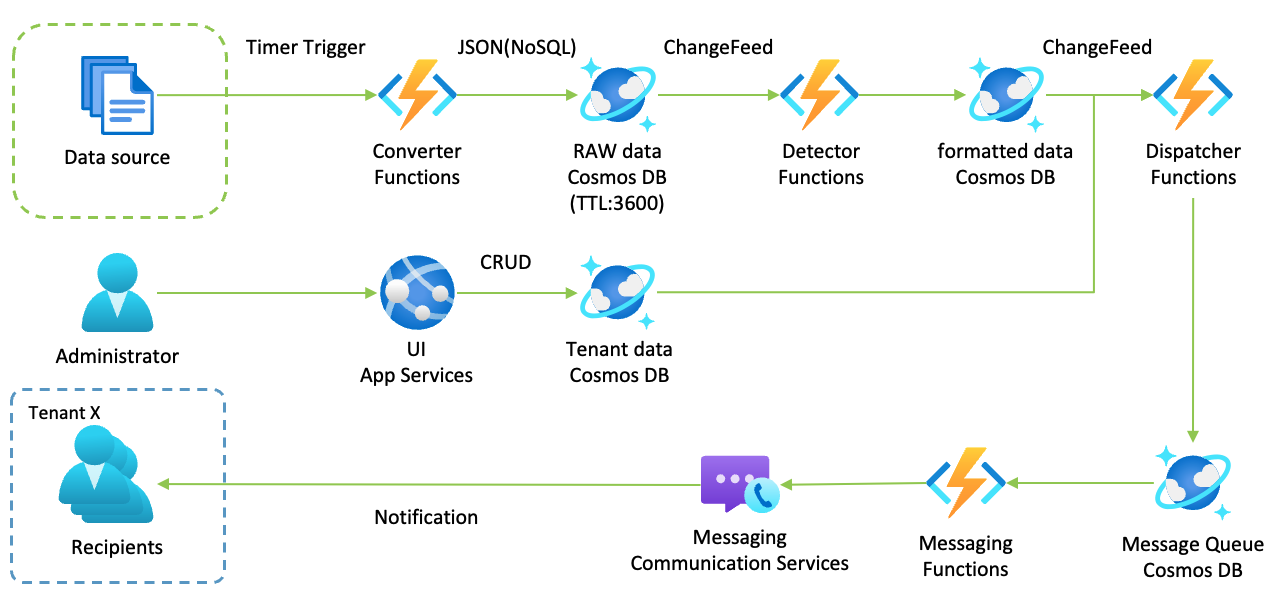
「ソースから定期的にデータを取得して生データを保管しつつ、新しいデータが到着して、一定の条件を満たした場合、テナントのユーザーにメッセージを飛ばす」というアプリをAzure Functions + Cosmos DBで実装しようとすると、以下のような構成(データフロー)になる。
そう、Cosmos DBは「ストリーミングを保管しつつ、ChangeFeedで次の処理をキックする」データストアだ。この絵に登場するCosmos DBは4つあるが、別にこれはCosmos DBのインスタンスが4つあることを意味しない。1つのCosmos DBインスタンスに、4つのコンテナ(コレクション)があるだけかもしれないし、AdministratorとApp Servicesの間にTraffic ManagerやFront Doorを入れている場合、Cosmos DBは複数のリージョンにインスタンスが存在するかもしれない。
いずれにしても、RDBMSであればこういうフローはやらない(やれない)はずだ。
マルチなコンシューマ
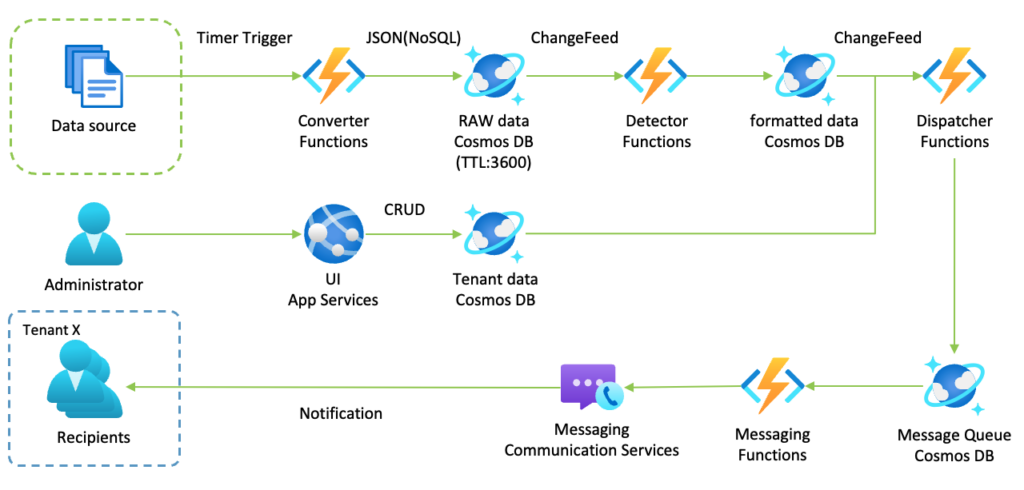
上のRAW dataは、TTL(Time To Live)に3,600秒が設定されているので、生データは1時間すると自動的にCosmos DBから削除される。こうすることでCosmos DBのストレージのコストを抑えることができる。一方で古いデータを分析に使いたい場合は、どうするかというとChangeFeedをStorage Accountにも繋げば良い。すると、RAW dataに入ってきたデータはすべからくStorage Accountに保存され、自動的に削除されることはない。
つまり、Cosmos DBはPub / Subモデルを使うことを最初から想定している。というのも、元々、Cosmos DBというか前身のDocument DBが、メッセージキューであるKafka無しにPub / Subモデルを実現することを設計に含んでいたからだ。(BW-Treeがそもそも「デルタノード」という差分を、いかにツリーに高速に追加するか、の実装である)
従って、ChangeFeedをいくつもくっつけて、コンシューマーをいくらでも増やせるというフレキシビリティを活用するのが正しい。
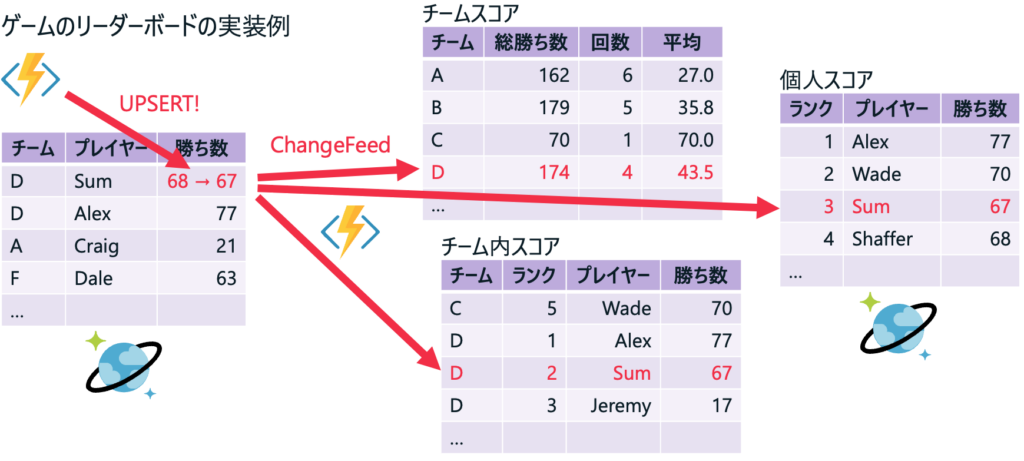
オンラインゲームのリーダーボードを実装するのも簡単。あるプレイヤーのデータが更新されたら、そのプレイヤーが所属するチーム(ギルドかもしれない)のスコア、チーム内のスコア、個人のランキングといったものを複数のChangeFeed + Functionsで別のCosmos DBのコンテナに格納されば良い。それぞれのFunctionsはパラ(並列)に実行されるので、いずれかのスコアの更新が滞るといったことも起きない。
いつやるの?今でしょ!
SELECTで複雑なJoinしたり、いくつものテーブルからサブクエリーで引っ張ってきたり、読み出し時にコストの高い処理をするのはやめよう。ChangeFeedを使うと、データが書き込まれた時に処理するというフローが簡単に作れるので、データが入ってきたタイミングで読み出し時に必要なデータを揃えてしまおう。
上述のゲームのリーダーボードの例が正にこれ。チームのスコアを読み出す時に、チームのテーブルからチームIDを取得し、プレイヤーのテーブルからチームIDに該当するプレイヤーのスコアを取得して集計する、のでは表示に時間がかかる。チームのスコアが確定するのは読み出し時ではなく、プレイヤーのスコアが変わった時なのだから、それから読み出し時までは時間があるはずだ。であれば、その時間にチームのスコアを先んじて計算しておくのが、レスポンスの良いアプリの作り方だ。
これはCosmos DBに限った話ではなく、PostgreSQLであればpg_cronを使って定期的に事前集計をする、あるいはpgnotifyでCosmos DBのChangeFeedと同じようなことは実装可能なので、事前にやれることはやっておこう。
リソースをケチらない
そもそもRDBMSにおける正規化というのは、ある事実を1箇所にのみ記録して、そこだけを更新すれば良いという理由もあるのだけど、ストレージのコストが高かった時代の考え方だ。今はとても安いのでデータを冗長に保持してもコスト上は大した問題ではない。それよりも、レスポンスの良さや回復性が求められるのだから、上述のデータを処理するタイミングを読み出し時ではなく書き込み時に移動するということがまず一つ。そして、上述のゲームのリーダーボードのチーム内スコアを見ると分かる通り、プレイヤーの名前を冗長に持っている。つまり、チーム内スコアを表示するのに必要なデータは全てこの(データ)コンテナに複製しておく。Joinやサブクエリーは必要ない。
準備編
Azure FunctionsをPythonで書くのにあたってVSCodeが便利というか、書いたコードをデプロイするのにVSCodeが一番楽なこともあるし、GitHub Copilotによる補完機能を利用しない手は無いので、やはりVSCode一択ということになるかと。ただしApple Siliconでは以下の問題があるので、これをやってから。
VSCodeの準備
まずいくつかローカルの環境を整える必要がある。VSCodeの拡張機能として以下が必要。
- Azure Account
- Azure Functions
- Azure Resources
- Azurite
- Python
- GitHub Copilot(オプションだけど、あった方が絶対に楽)
VSCodeの拡張機能であるAzuriteは、Azure Storage Accountをエミュレートする。ローカルで実行する時のログなどの保存先になるので、VSCodeを起動したらコマンドパレットから[Azurite: Start]しておく。
requirements.txtには、最低限以下が必要。
- azure-functions
- azure.cosmos
残りはPythonのコードの中でimportして引っかかったら、.venvのpipで追加。ローカルで追加したものは、Azureへのデプロイ時にマニフェストに自動的に追加される。
% source .venv/bin/activate
(.venv) % python3 -m pip install some_module実装編
Cosmosコンテナーの作成
おそらく、一番ひっかかるのはパーティションキーの設定だろうし、このパーティションキーこそがCosmosの勘所ではあるので、公式ドキュメントを読むことをオススメしつつ、でも、とっとと使ってみたいということであれば、”/id”に設定してPythonから読み書きしてみると良い。
アプリケーション設定
ローカルとAzure上でFunctionsの設定を保持する方法は異なっている。
- ローカル:local.settings.jsonに保持。このファイルはデフォルトで.funcignore / .gitignoreに含まれているので、AzureにもGitHubにもデプロイはされない。このファイルに設定値を入れておく。
- Azure上:AzureポータルのFunctionsの[構成][アプリケーション設定]でも設定できるが、VSCodeで、コマンドパレット([Command] + [Shift] + [P])から[Azure Functions: Add New Setting…]から設定する方が早い。
設定した値はローカルでもAzure上でも環境変数として読み出せるので、以下のようなコードで。
import os
cosmos_con_str = os.environ["COSMOS_CON_STR"]ただしエントリーポイントになってない、例えばtest.pyみたいなスクリプトからlocal.settings.jsonを利用するには、こんな感じの関数を用意して環境変数にロードしておくのが便利。
def load_localsettings_json():
open_settings = open("local.settings.json", "r")
settings = json.load(open_settings)
open_settings.close()
for key in settings["Values"]:
os.environ[key] = settings["Values"][key]Azure KeyVaultの利用(オプション)
Azure Functionsの[構成][アプリケーション設定]から値を見られるとセキュリティ上のリスクとなるパターンも考えられる。つまりロールベースのアクセスコントロール上、ポータルへのアクセスを禁止出来ないメンバーがいる、みたいなことだ。この場合はAzure KeyVaultに値を保存し、KeyVaultへのキーやRBACを適用することになる。
KeyVaultの利用方法はそれほど難しくない。AzureポータルでKeyVaultのキーコンテナを作成し、キーコンテナへのアクセス許可を付与しておく。
ローカル側では、az loginする。
% az loginモジュールをインストールし、
(.venv) % python3 -m pip install azure-identity azure-keyvault-secretsコードで設定したキーを読み出すだけだ。
from azure.keyvault.secrets import SecretClient
from azure.identity import DefaultAzureCredential
keyVaultName = os.environ["KEY_VAULT_NAME"]
KVUri = f"https://{keyVaultName}.vault.azure.net"
credential = DefaultAzureCredential()
client = SecretClient(vault_url=KVUri, credential=credential)
cosmos_con_str = client.get_secret("COSMOS_CON_STR")デプロイしたFunctionsはマネージドキーなので、コードの変更などは必要ない。
Cosmos DB ChangeFeed Trigger
上のリンク記事を見れば分かるように、cosmos_db_triggerのデコレータは最低4つの引数を取る。lease_containerなどはOptionalなので必要に応じて追加すれば良い。
@app.cosmos_db_trigger(arg_name="documents",
database_name=os.environ["DATABASE_NAME"],
container_name="container1",
connection="COSMOS_CONNECTION")
def cosmos_changefeed1(documents: func.DocumentList) -> str:
if document:PythonのCosmos ChangeFeedのDocument
正確には、azure.functions.DocumentList。
共有ライブラリ
別に難しいことはなく、
shared/utils.py
.funcignore
.gitignore
function_app.py
host.json
local.settings.json
requirements.txt
という配置にして、
from shared import utilsとすれば良い。
Gremlin API
グラフデータを扱うにはNoSQLではなくGremlin APIの方が便利。CSVを読んで、Vertexを追加し、Vertex間にEdgeを設定するコード。
with open(path, "r") as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
query = "g.addV('p').property('id', '{0}')".format(row[2])
execute_query(client, query)
words = parse_desc(client, row[5])
for word in words:
query = "g.addV('w').property('id', '{0}').property('pk', 'pk')".format(word)
execute_query(client, query)
query = "g.V('{0}').addE('has').to(g.V('{1}'))".format(row[2], word)
execute_query(client, query)Pythonだとnetworkxでグラフデータを扱えるので、networkxをGremlin APIでCosmosに書き込む、あるいはCosmosから読み出したグラフをnetworkxに入れて演算する、といったことが可能。
デバッグ編
ロギングレベル
トラブルシュート編
プロジェクトディレクトリを移動した時
Azure FunctionsのPythonは.venvで実行されるので、project_directory/.venv/bin/以下に絶対パスでプロジェクトディレクトリが書き込まれている。移動すると、cwd (change working directory)に失敗し、成功しても.venvのパスが違うから動かなくなる。
% cd project_directory/.venv/bin
% grep "project_directory"して見つかったテキストファイルを修正する。pycは削除して問題なし。
Undocumented
残念ながらCosmos DBのPython SDKに関する情報は限られているし、公式ドキュメントも絶対に正しいとは限らない。(そのうち正しくなるかもしれないので、Eventual Consistencyである。)最も確実なのはGitHubで公開されているazure-functions-python-libraryを見ること。Pythonで書かれているので、ランタイムを読むよりはずっと楽。
