この声優さん、確かこの作品であの声優さんと共演してたよなぁ
はじめに
(この記事はMicrosoft Azure Tech Advent Calendar 2023シリーズ2の12月6日のエントリーです)
「ある声優さんが別の声優さんと共演してたよなぁ」って、知りたくなりません?
オタクは知りたいです。
2023年冬アニメでは『葬送のフリーレン』が猛威を振るっておりますが、同じ冬アニメの『SPY×FAMILY』、『魔法使いの嫁』、『薬屋のひとりごと』、共通点は分かりますか?
そうですね、種﨑敦美さんが出てる作品です(他多数にも出演されてますが)。フリーレン役とアーニャ役が同じ声優さん?!ってなると思いますが、まずはこれを知りたくなるわけです、オタクとしては。
で、さらに『葬送のフリーレン』と『SPY×FAMILY』で共演してる声優さんは、誰と誰だ?って知りたくなるわけですね。(フリーレン役・アーニャ役=種﨑さん、シュタルクの兄シュトルツ役・ロイド役=江口拓也さん)
これを、Wikipediaで「声優A→作品A→声優B」というように探すの、辛いです。
じゃあどうするかっていうことなんですが、こういう「関係」とか「関連」とかに特化したデータ構造、つまりグラフデータにしちゃえば良いんです。
PythonでXMLをパースする
データの入手
コードの説明に行く前に、データを入手しましょう。
Wikipediaはダンプデータを配布してくれているのでクロールは不要です(クロールは禁止されてます)。ダンプのインデックスページからダウンロードできます。最新の日本語版の記事データはURLが固定されているので、更新することを考えるとそちらからダウンロードするようにするのが良いでしょう。執筆時点では4.1GBほどの圧縮されたファイルでした。
このファイルを展開すると、17GB近いXMLファイルになるのでファイルの置き場所には注意してください。
遅延評価を使おう
さて、このぐらい大容量のファイルをPythonで読んでXMLをパースしてDictにして、とバカ正直にやるとメモリをバカ食いして死ねます。Generatorを使って処理しましょう。こんな感じです。
def file_read_generator(file_path: str, start_sep: str = '<page>', end_sep: str = '</page>') -> str:
txt = ''
in_page = False
with open(file_path, 'r') as f:
for line in f:
if in_page == True:
txt += line
if end_sep in line:
yield txt
txt = ''
else:
if start_sep in line:
in_page = True
txt += line
for page in file_read_generator(file_path):
dic = xmltodict.parse(page)
......要は<page></page>で囲まれた部分だけ読んだらyieldして、関数の実行を中断するやつですね。遅延評価はこういう時に便利です。
出演作品を抜き出そう
次に、Dictに変換した中から説明文を抜き出して、リストにします。
def extract_appearance_list(content: str) -> list:
is_appear = False
is_voice_actor = False
txt = ''
appearance_list = []
for line in content.split('n'):
if '== 出演 ==' in line:
is_appear = True
continue
if is_appear == True:
if ('=== 声優 ===' in line) or ('=== テレビアニメ ===' in line) or ('=== 劇場アニメ ===' in line):
is_voice_actor = True
continue
if is_voice_actor == True:
if line == '':
break
m = prog_title_re.search(line)
if m != None:
g = m.groups()
appearance_list.append(g[0].replace("'", """))
return list(set(appearance_list))ここでは主にテレビアニメと劇場アニメだけを抜き出していますが、OVAとかもっと完全に網羅したいオタクは、条件を追加してください。
あとはGremlin APIを叩いてデータを登録すれば良いだけですが、先に、Cosmos DB for Apache Gremlinのアカウントを作りましょう。
Cosmos DB for Apache Gremlin
Cosmosアカウントの作成
Azureポータルにアクセスして、[リソースの作成]をクリックします。

左のブレードで[データベース]をポイントして、[Azure Cosmos DB]の[作成]をクリックします。
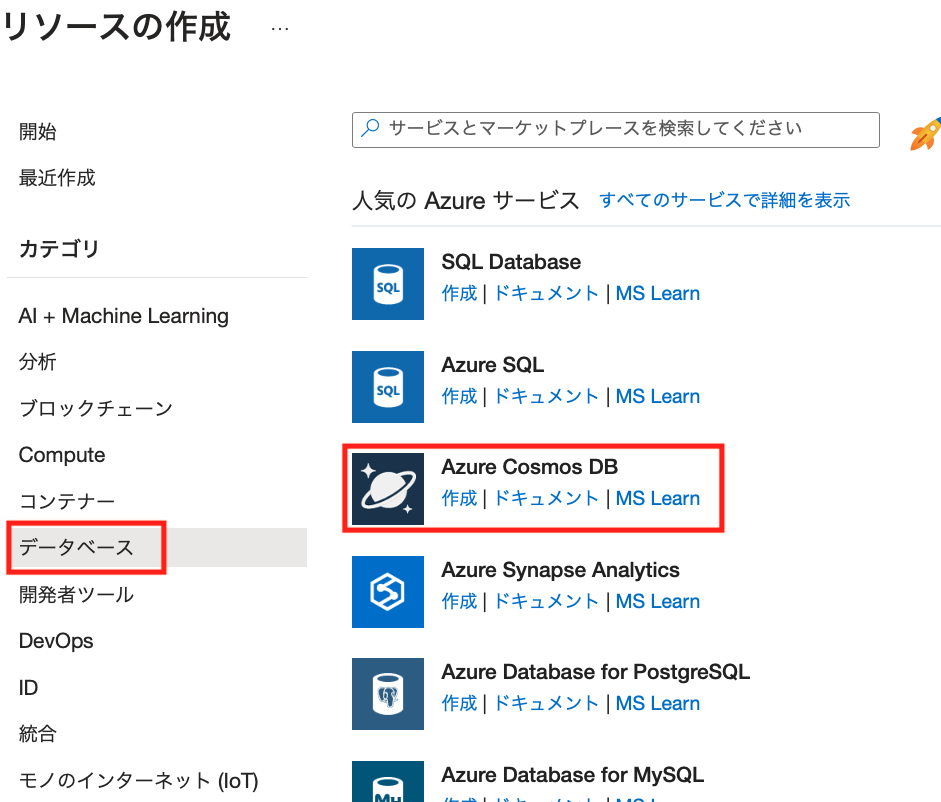
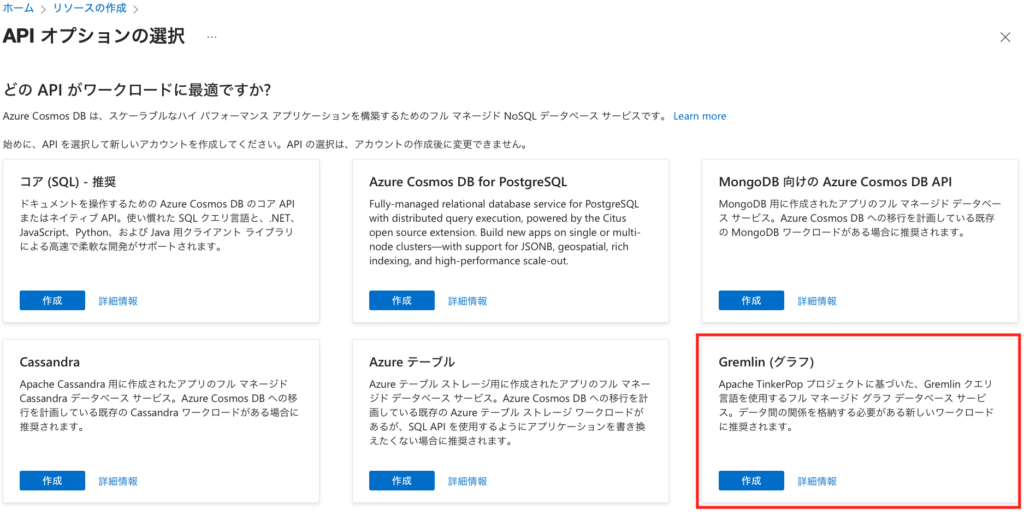
[APIオプションの選択]で[Gremlin]の[作成]ボタンをクリック。
利用するサブスクリプションを選択したら、[リソースグループ]、[アカウント名]、[場所]を選択・入力します。
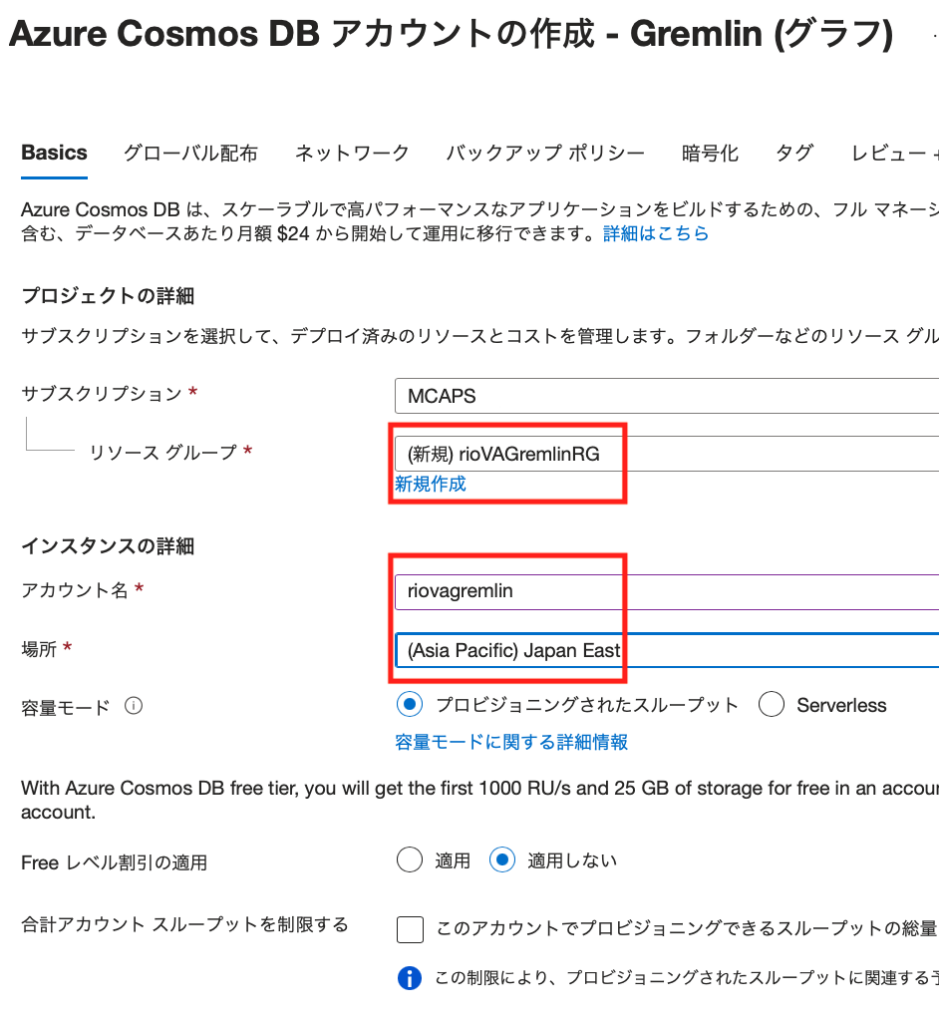
あとは[作成]ボタンをクリックすればデプロイが始まります。
Cosmosの接続設定その1
後ほど、PythonスクリプトからCosmosに接続する際に、Cosmosの[キー]に表示される、[GREMLIN URI]と[PRIMARY KEY]が必要になります。
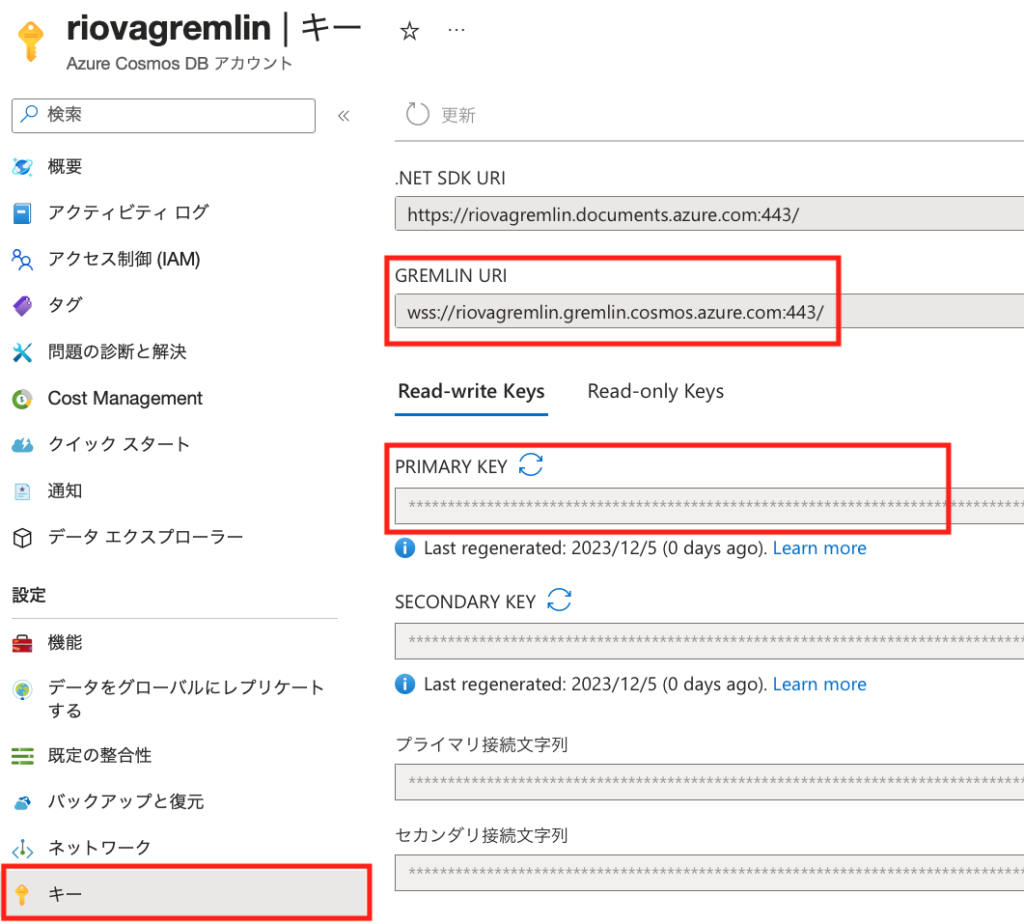
PythonのGremlinモジュールで接続する際の"password"パラメータは、この[PRIMARY KEY](もしくは[SECONDARY KEY])になります。
Cosmosの接続設定その2
次に、Cosmosのデータベースとコレクション(データコンテナ)を作成します。[データエクスプローラー]から[New Graph]をポイントします。
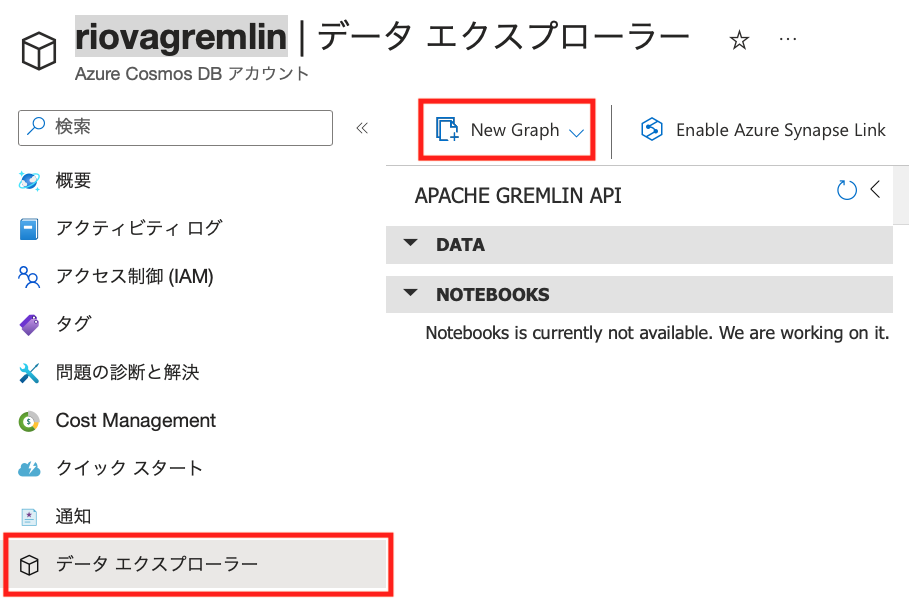
画面右側に[New Graph]というブレードが表示されるので、[Database id]、[Graph id]、[Partition Key]を設定します。ここに表示されている例の通りに入れてもらえば、Pythonのコードの修正は必要ありません。
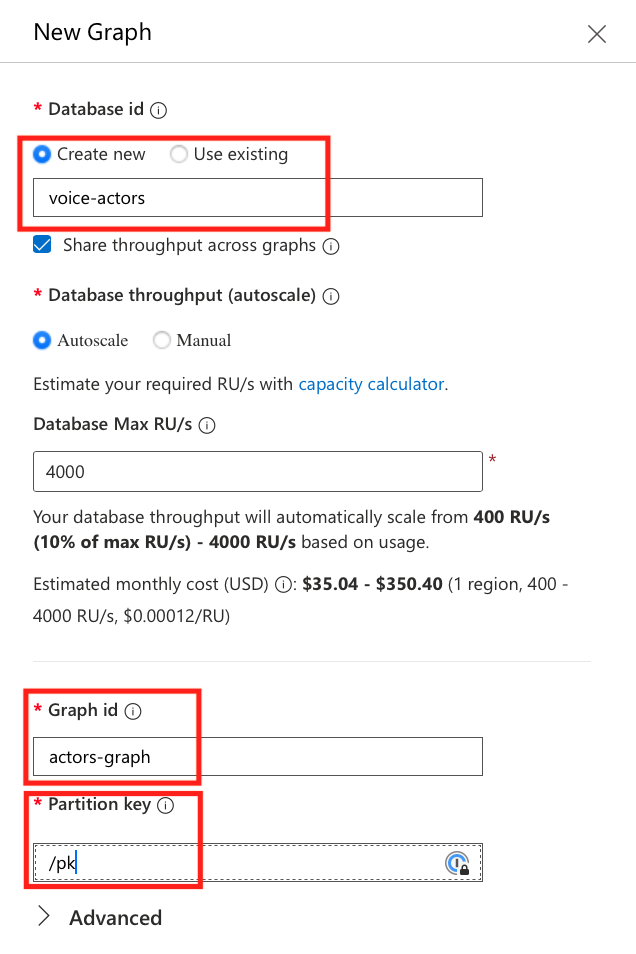
PythonのGremlinモジュールで接続する際の"username"パラメータは、
username = "/dbs/{database_name}/colls/{graph_id}"という形式になります。
Gremlin APIでデータを登録する
完成したコード例は以下です。GitHubにも置いておきます。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import hashlib
import os
import re
import sys
import xmltodict
# third party library
try:
from gremlin_python.driver import client, serializer, protocol
from gremlin_python.driver.protocol import GremlinServerError
except ModuleNotFoundError:
try:
os.system('python3 -m pip install gremlinpython')
from gremlin_python.driver import client, serializer, protocol
from gremlin_python.driver.protocol import GremlinServerError
except ModuleNotFoundError:
print('Please install gremlinpython with brew: brew install gremlinpython')
sys.exit(1)
# to extract the program titles from the text of a Wikipedia page
prog_title_re = re.compile(r"^*+ [[(.+?)]]")
# Execute a Gremlin query and print results.
def execute_query(client, query):
print("n> {0}n".format(query))
try:
callback = client.submitAsync(query)
if callback.result() is not None:
print("tExecuted this query:nt{0}".format(callback.result().all().result()))
else:
print("Something went wrong with this query: {0}".format(query))
print("n")
print("tResponse status_attributes:nt{0}n".format(callback.result().status_attributes))
except GremlinServerError as e:
if e.status_code == 409:
print("tAlready existsn")
pass
# Read the XML file and return a generator that yields the text of each page.
def file_read_generator(file_path: str, start_sep: str = '<page>', end_sep: str = '</page>') -> str:
txt = ''
in_page = False
with open(file_path, 'r') as f:
for line in f:
if in_page == True:
txt += line
if end_sep in line:
yield txt
txt = ''
else:
if start_sep in line:
in_page = True
txt += line
def escape_appearance(appearance: str) -> str:
result = appearance.replace("'", '’')
result = result.replace('/', '/')
result = result.replace('?', '?')
return result
# Extract the appearance list from the text of a Wikipedia page.
def extract_appearance_list(content: str) -> list:
is_appear = False
is_voice_actor = False
txt = ''
appearance_list = []
for line in content.split('n'):
if '== 出演 ==' in line:
is_appear = True
continue
if is_appear == True:
if ('=== 声優 ===' in line) or ('=== テレビアニメ ===' in line) or ('=== 劇場アニメ ===' in line):
is_voice_actor = True
continue
if is_voice_actor == True:
if line == '':
break
m = prog_title_re.search(line)
if m != None:
g = m.groups()
appearance_list.append(g[0].replace("'", '"'))
return list(set(appearance_list))
def main():
# Create a Gremlin client.
gr_client = client.Client('wss://riovagremlin.gremlin.cosmos.azure.com:443//', 'g',
username="/dbs/voice-actors/colls/actors-graph",
password="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx==",
message_serializer=serializer.GraphSONSerializersV2d0()
)
# Drop the entire Graph
execute_query(gr_client, "g.V().drop()")
file_path = 'jawiki-20231201-pages-articles-multistream.xml'
for page in file_read_generator(file_path):
if ('Category:日本の男性声優' in page) or ('Category:日本の女性声優' in page):
page_dict = xmltodict.parse(page)
actor = page_dict['page']['title'].replace("'", """)
# extract appearance list
appearance_list = extract_appearance_list(page_dict['page']['revision']['text']['#text'])
# Firstly add vertex of voice actor
query = "g.addV('actor').property('id', '{0}').property('label', '{1}').property('pk', 'pk')".format(actor, actor)
execute_query(gr_client, query)
# Next, add vertices of appearance and edges
for appearance in appearance_list:
escaped_appearance = escape_appearance(appearance)
query = "g.addV('appearance').property('id', '{0}').property('label', '{1}').property('pk', 'pk')".format(escaped_appearance, appearance)
execute_query(gr_client, query)
query = "g.V('{0}').addE('has').to(g.V('{1}'))".format(actor, escaped_appearance)
execute_query(gr_client, query)
if __name__ == "__main__":
main()105行のg.addV()で声優を、110行のg.addV()で出演した作品を表すVertex(頂点)を追加し、112行のg.V().addE()で、声優と作品を繋ぐEdgeを設定しています。複数の声優が同じ作品に出演している場合、
- 声優Aを追加
- (声優Aが出演した)作品Aを追加
- 声優Aと作品Aを繋ぐ
- 声優Bを追加
- (声優Bが出演した)作品Aを追加
- 声優Bと作品Aを繋ぐ
という処理が行われ、声優A⇔作品A⇔声優B、というデータ構造ができあがります。
簡単にするためにpassword等の接続文字列をコードに埋め込んでいますが、本番では絶対にやらないでください!Azure Keyvaultや、Managed Identity等の利用を必ず検討してください。
コードを実行すると、Cosmos DBにデータが投入されます。
クエリーしてみる
さて、ここからが楽しい時間です。延々とグラフをいじっていられるので、注意してくださいw
Azureポータルを開いて、先に作成したCosmos DBのアカウントを表示します。[データエクスプローラー]の"voice-actors"から"actors-graph"をポイントし、さらに[Graph]をポイントすると、クエリーを入力するフィールドが表示されます。画面内の"<"や">"をクリックすると、中央のグラフ表示の面積が広くなります。
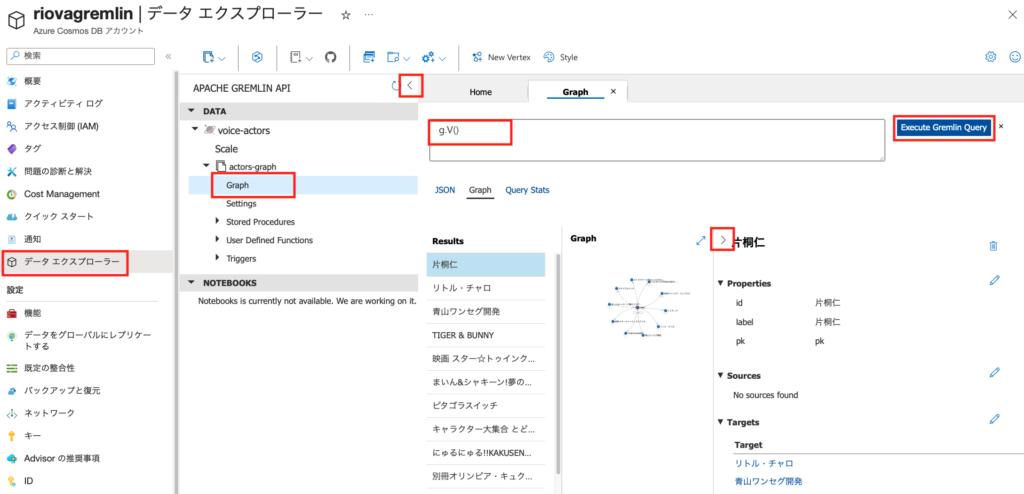
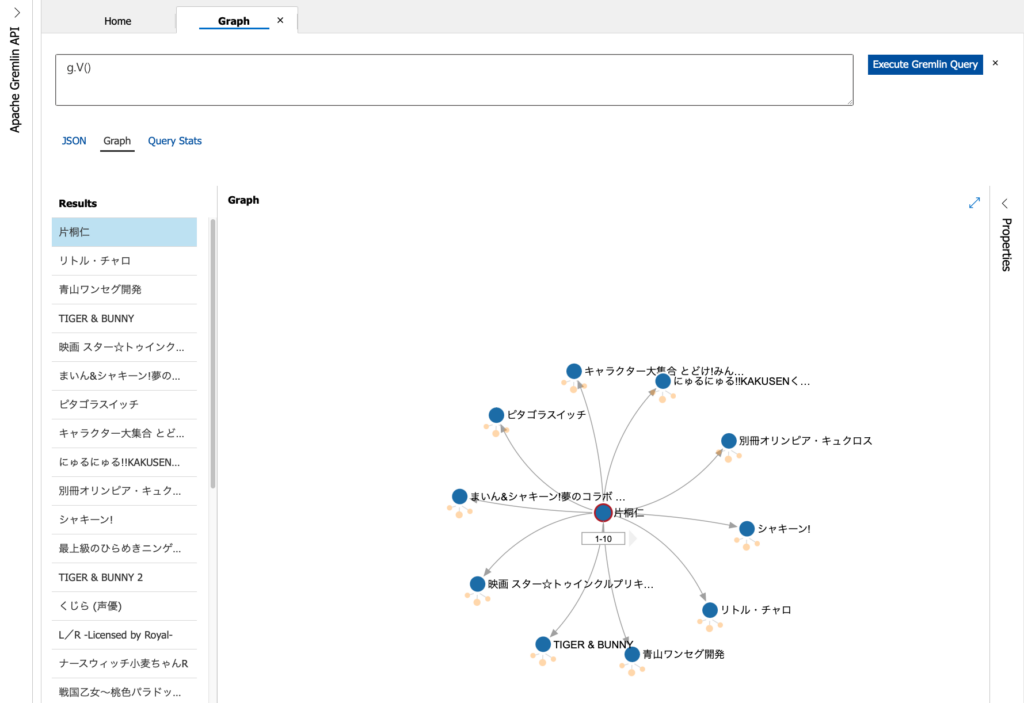
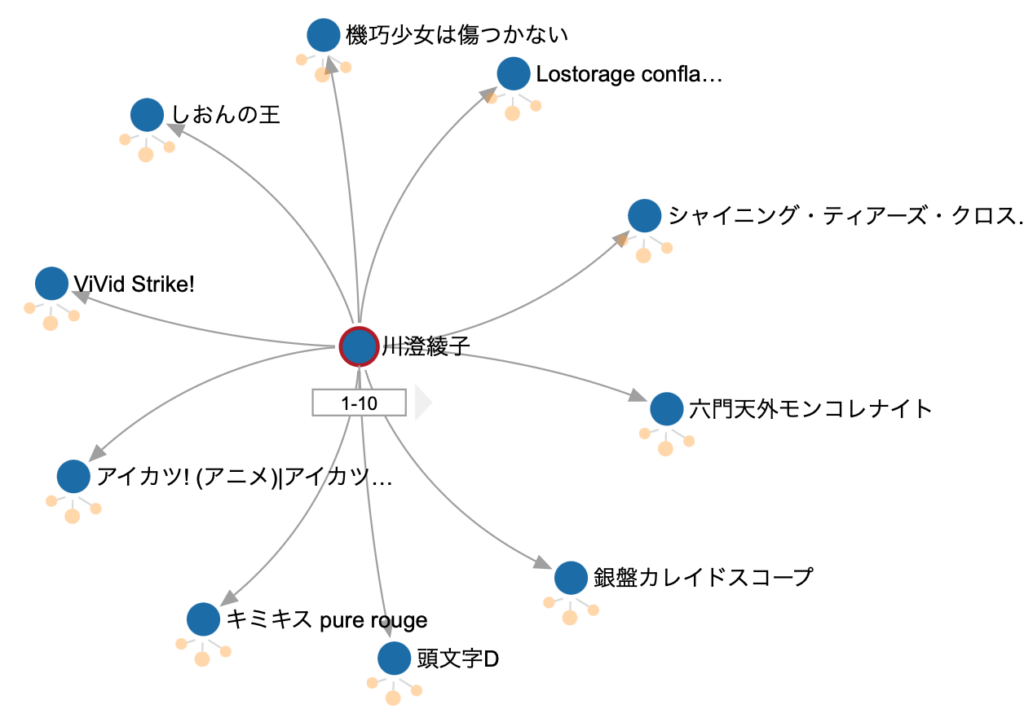
既に表示されていますが、クエリーの入力フィールドに"g.V()"、「全ての頂点を検索する」クエリーを入力して、[Execute Gremlin Query]ボタンをクリックすると、片桐仁さん(「ギリジン」さんですねw)が表示されます。
ここから静止画では説明しにくいので動画も用意しました。各頂点をドラッグして移動したり、頂点の下にある薄いオレンジ色の3つの円をクリックしてみてください。
では、三木眞一郎さんの出演作品を探してみましょう。
g.V('三木眞一郎')もちろん、出演作品から声優さんを見つけることも可能です。
g.V('江戸前エルフ')能登麻美子さんが出演した作品は以下のクエリでJSONが返ってきます。
g.V('能登麻美子').outE()この作品に出演した他の声優を見つけるには、以下ですね。
g.V('能登麻美子').outE().inV()これは以下のように書いても同じです。
g.V('能登麻美子').out()まとめ
Gremlin APIで実装しているのは、Apache TinkerPopというグラフコンピューティングのフレームワークのクエリー言語です。このエントリーでは簡単なクエリーのみを紹介しましたが、より複雑なクエリーを実行して「あの声優さんとこの声優さん、ここで繋がってるのか!」という発見をするには、リファレンスと首っ引きになるのがオススメですw

