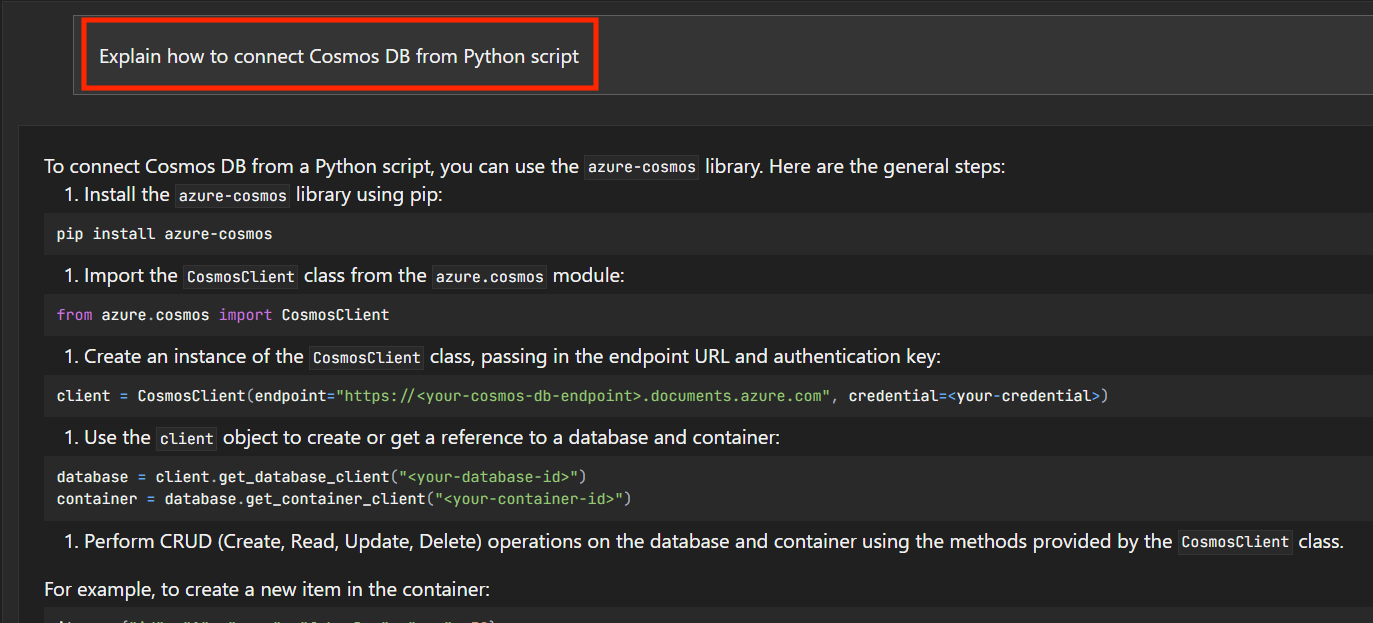
NVIDIAがChat with RTXをリリースしてくれたので、GitHubからcloneしてシコシコビルドせずとも、アプリをダウンロードするだけでRAG(Retrieval Augmented Generation)を利用できるようになった。最も簡単なのは、Chat with RTXにYoutubeのURLを食わせる方法なのだけど、圧倒的にRAGのベースとなるデータ量としては少ない。
さて、何を食わせるかなぁと考えて、まだChat with RTXが英語にしか対応していないことも鑑みて、MicrosoftのLearnを学習させてみることにした。
まず、en-usのazureだけクロールしてダウンロードする。これは一晩放置しておけば良い。
% wget -np \
--reject '*.js,*.css,*.ico,*.txt,*.gif,*.jpg,*.jpeg,*.png,*.mp3,*.pdf,*.tgz,*.flv,*.avi,*.mpeg,*.iso,*.svg,*.xml,*.docx'\
-r https://learn.microsoft.com/en-us/azure/次に、ダウンロードしたディレクトリにglob()して、ファイルから以下のような感じでコンテンツ部分だけ抜き出す。
def get_content(src):
in_content = False
buf = ""
for ln in src.split("\n"):
if "<!-- <content> -->" in ln:
in_content = True
buf = ln.strip() + "\n"
elif "<!-- </content> -->" in ln:
buf = buf + ln.strip() + "\n"
return buf
else:
if in_content == True:
buf = buf + ln.strip() + "\n"あとは、BeautifulSoupでテキストだけ抜き出して、テキストファイルとして保存する。
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, "html.parser")
print(soup.text)テキストファイルは約33,000個、容量は480MBのデータが得られた。
これをChat with RTXに食わせると、延々とEmbeddingを生成するので、数時間放置する。
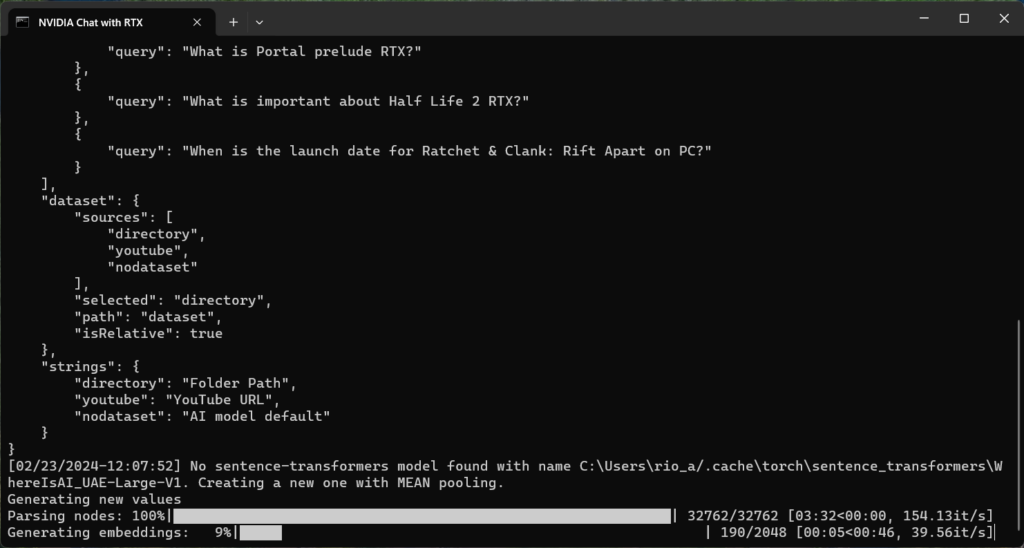
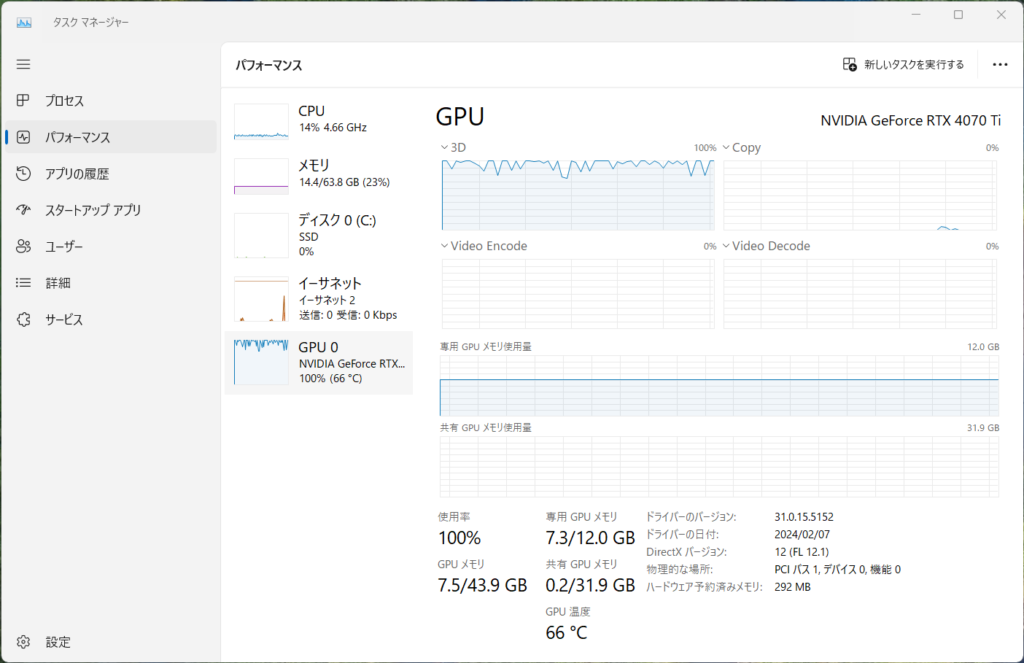
終わったら、質問してみる。
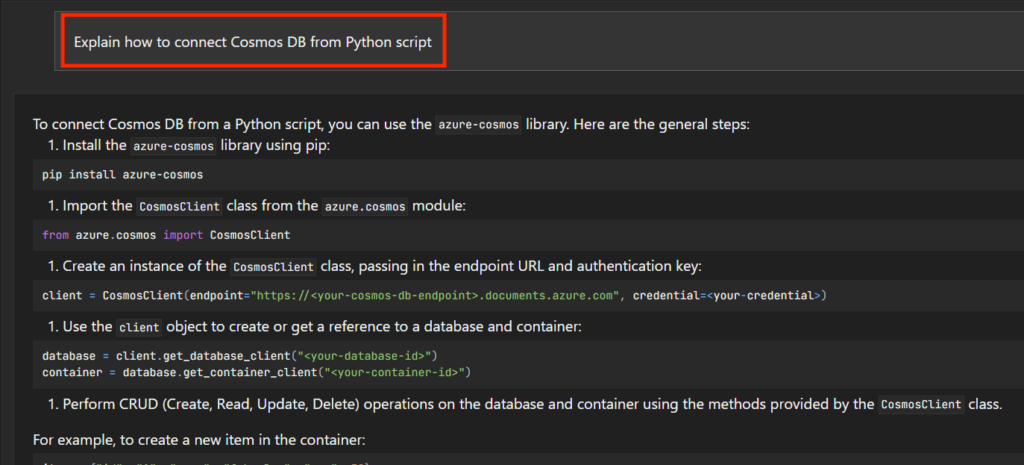
ちゃんと、回答のソースも表示される。
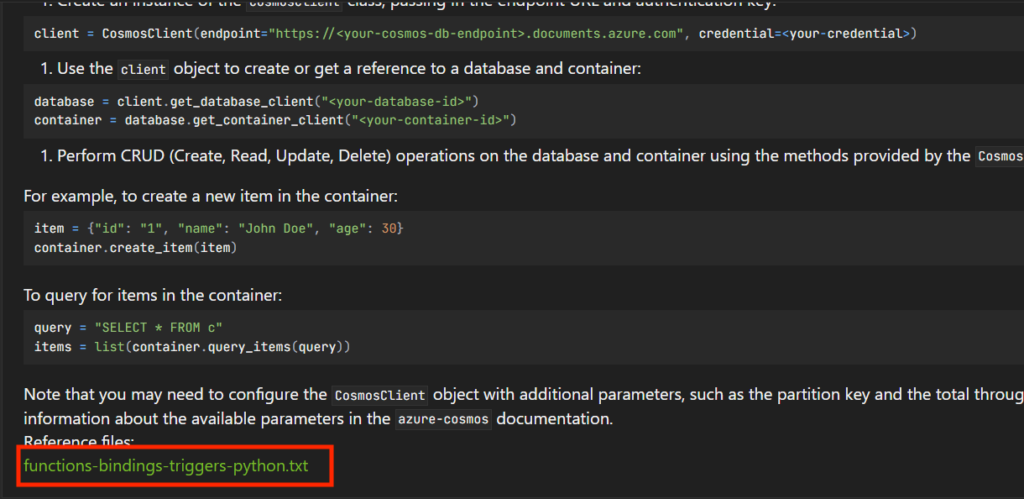
鼻血が出そうなぐらい便利なんですけど、これw