先日あるお客様との会話で、膨大なデータをグラフにするのに、pg_cronでaggregation(事前集計)をかけておけば、そのグラフをダッシュボードでインタラクティブにスケールを変更しつつ、少ないデータをfetchするだけで良いので、むっちゃ軽快な動作をするようにできまっせ、という話になった。
で、aggregationの内容はハンズオンラボ用に書いたPL/PGSQLを見てもらえば分かる通り、AVG / MIN / MAXを取るだけなので、折れ線グラフにした時に特徴を表すかというと非常に微妙、という説明をしたところ、そのお客様がLTTB(Largest Triangle Three Buckets)アルゴリズムというのがあって、という情報を提供してくれた。
不勉強なもので知らなかったため調べてみると、Qiitaに書いてくれてる人がいるので、まあそこからたどってGitHubのまとめページに行き着いた。特に難しいことをやってるわけではないのだけれど、残念ながらPL/PGSQLで書いてる人がおらん。PL/PGSQLで書かれてれば、CREATE FUNCTIONしてpg_cronで定期的に呼び出してやりゃイイ訳で、じゃ書くかと午前中から書いて今に至る、と。
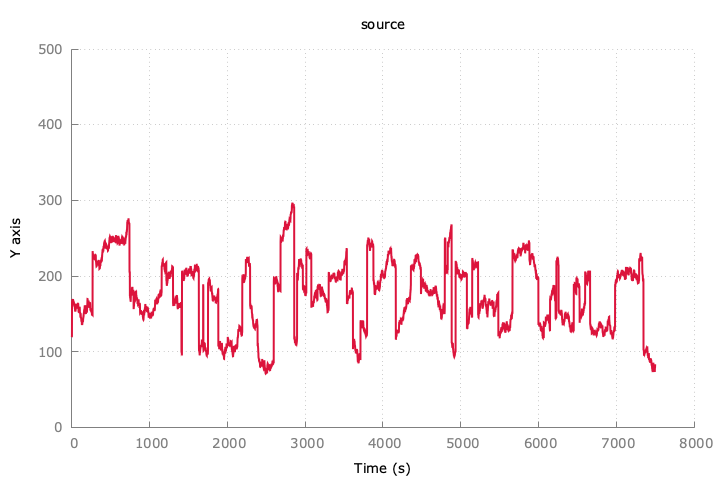
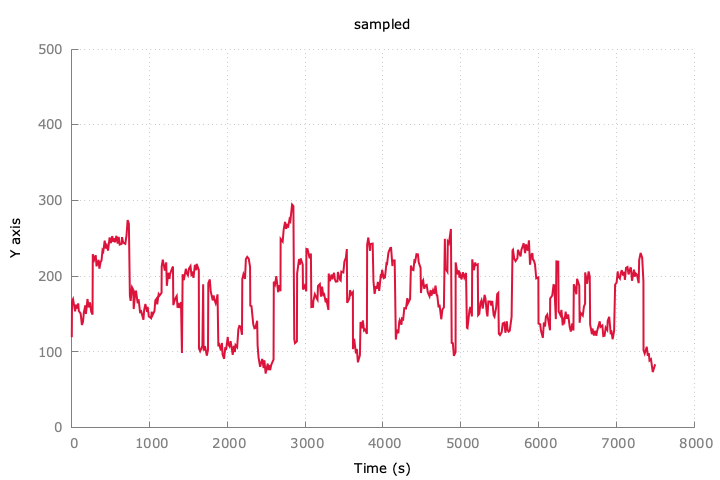
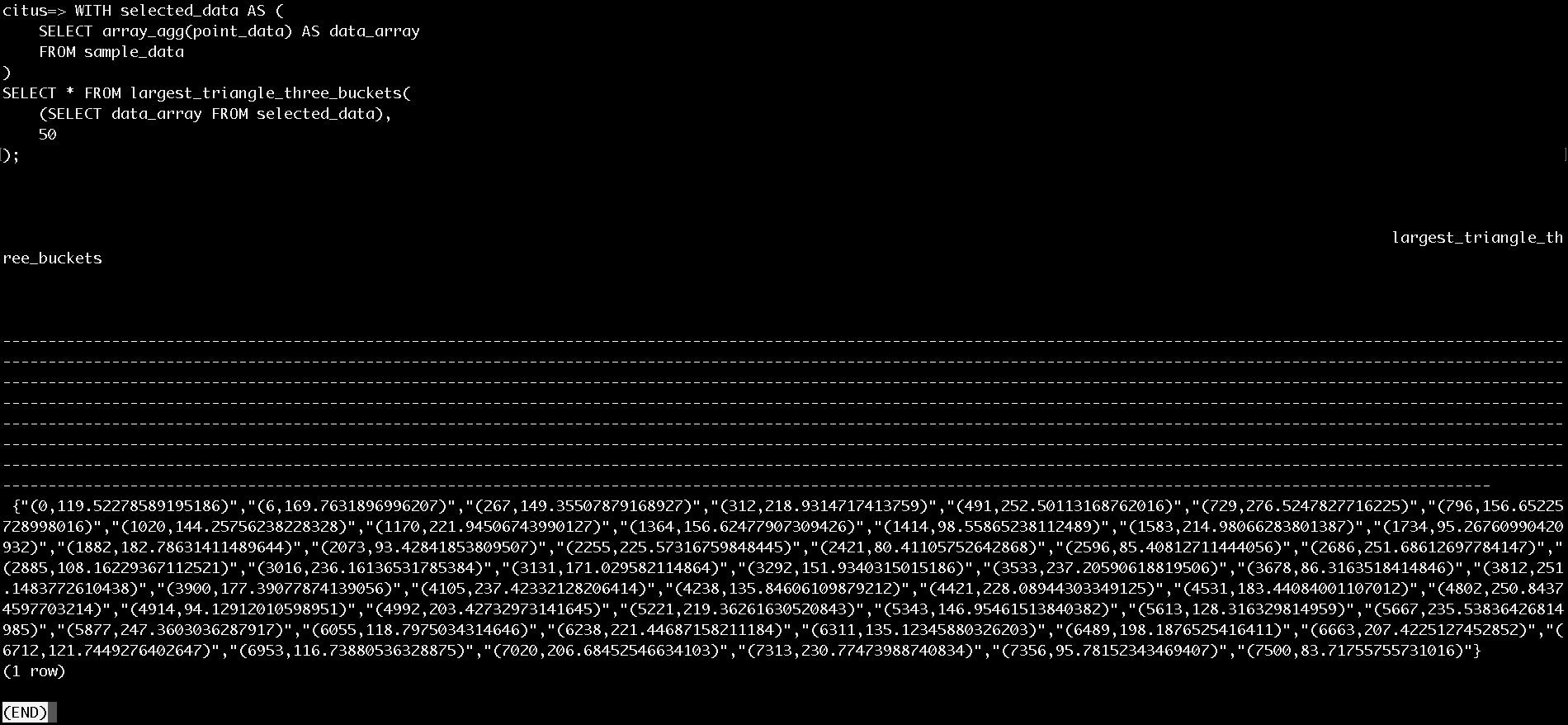
GitHubに放流しておいた。
CREATE OR REPLACE FUNCTION largest_triangle_three_buckets(data POINT[], threshold INT)
RETURNS POINT[] AS $$
DECLARE
a INT := 1;
next_a INT;
max_area_point POINT;
bucket_size DOUBLE PRECISION;
tmp_p POINT;
avg_x DOUBLE PRECISION;
avg_y DOUBLE PRECISION;
avg_range_start INT;
avg_range_end INT;
avg_range_length INT;
range_offs INT;
range_to INT;
point_ax DOUBLE PRECISION;
point_ay DOUBLE PRECISION;
max_area DOUBLE PRECISION;
area DOUBLE PRECISION;
sampled point[] := '{}';
BEGIN
-- Validate input data and threshold
IF array_length(data, 1) IS NULL OR threshold <= 2 OR threshold >= array_length(data, 1) THEN
RAISE EXCEPTION 'Invalid data or threshold';
END IF;
-- Initialize variables
bucket_size := CAST(array_length(data, 1) - 2 AS DOUBLE PRECISION) / (threshold - 2);
-- RAISE NOTICE 'bucket_size: %', bucket_size;
-- Always include the first data point
sampled := array_append(sampled, data[1]);
-- Downsample the data
FOR i IN 0..threshold - 3 LOOP
-- Calculate the average x and y values for the next bucket
avg_range_start := FLOOR((i + 1) * bucket_size) + 1;
avg_range_end := LEAST(FLOOR((i + 2) * bucket_size) + 1, array_length(data, 1));
avg_x := 0;
avg_y := 0;
avg_range_length := avg_range_end - avg_range_start;
-- RAISE NOTICE 'avg_range_length: %', avg_range_length;
FOR j IN avg_range_start..avg_range_end - 1 LOOP
tmp_p := data[j];
avg_x := avg_x + tmp_p[0];
avg_y := avg_y + tmp_p[1];
END LOOP;
avg_x := avg_x / avg_range_length;
avg_y := avg_y / avg_range_length;
-- RAISE NOTICE 'avg_x: %', avg_x;
-- RAISE NOTICE 'avg_y: %', avg_y;
-- Determine the point that forms the largest triangle with point a and the average point
max_area := -1;
range_offs := FLOOR(i * bucket_size) + 1;
range_to := FLOOR((i + 1) * bucket_size) + 1;
tmp_p := data[a];
point_ax := tmp_p[0];
point_ay := tmp_p[1];
FOR j IN range_offs..range_to - 1 LOOP
tmp_p := data[j];
area := ABS((point_ax - avg_x) * (tmp_p[1] - point_ay) - (point_ax - tmp_p[0]) * (avg_y - point_ay)) * 0.5;
IF area > max_area THEN
max_area := area;
max_area_point := data[j];
next_a := j;
END IF;
END LOOP;
-- Add the point with the largest area to the downsampled data
sampled := array_append(sampled, max_area_point);
a := next_a;
END LOOP;
-- Always include the last data point
sampled := array_append(sampled, data[array_length(data, 1)]);
RETURN sampled;
END;
$$ LANGUAGE plpgsql;pg_cronで使うなら、largest_triangle_three_buckets()にクエリ結果とthresholdを引数として渡すように変更すればよろし。
追記:sin波をダウンサンプリングするとどうなるのか。
-- 100件にダウンサンプリングするクエリ
WITH selected_data AS (
SELECT array_agg(POINT(x, sin(radians(x)))) AS data_array
FROM generate_series(-180, 180, 0.1) AS x
)
SELECT * FROM largest_triangle_three_buckets(
(SELECT data_array FROM selected_data),
100
);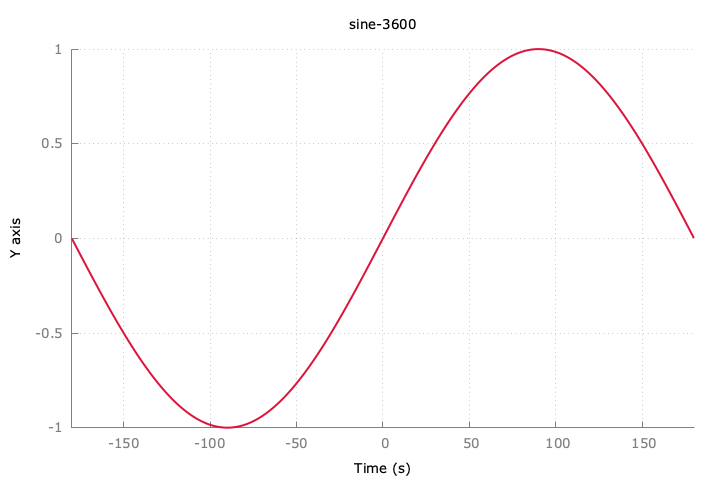
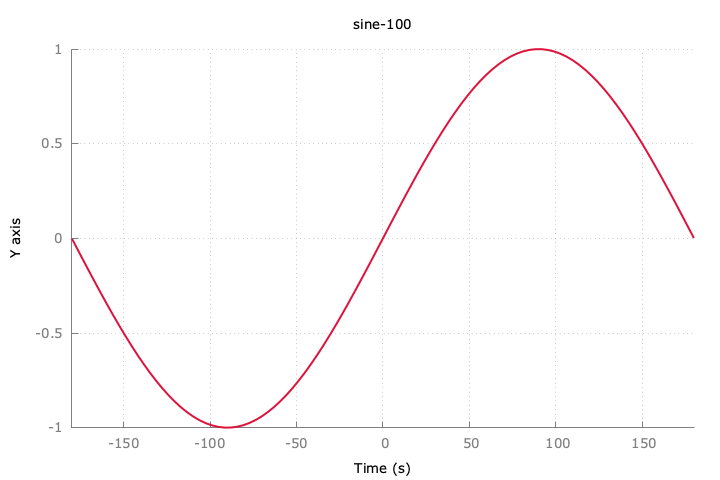
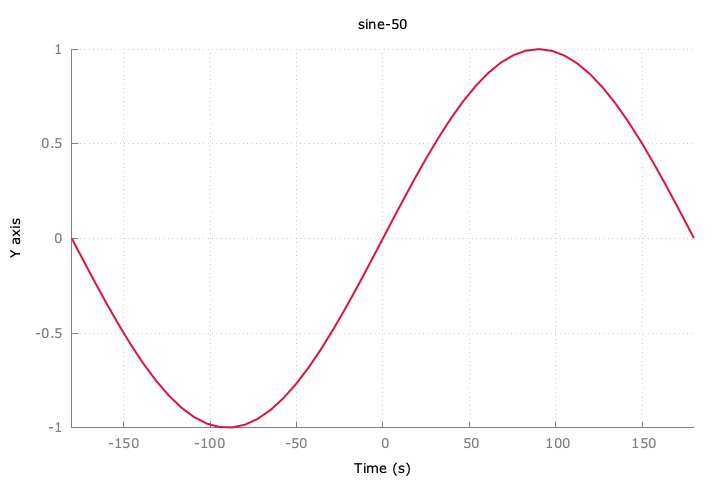
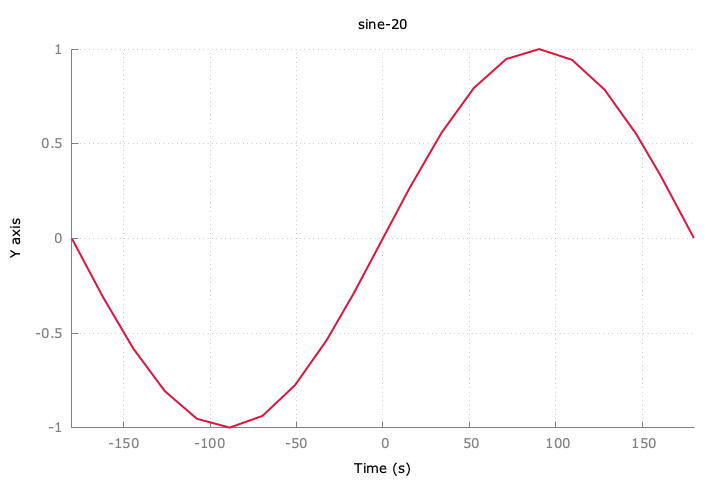
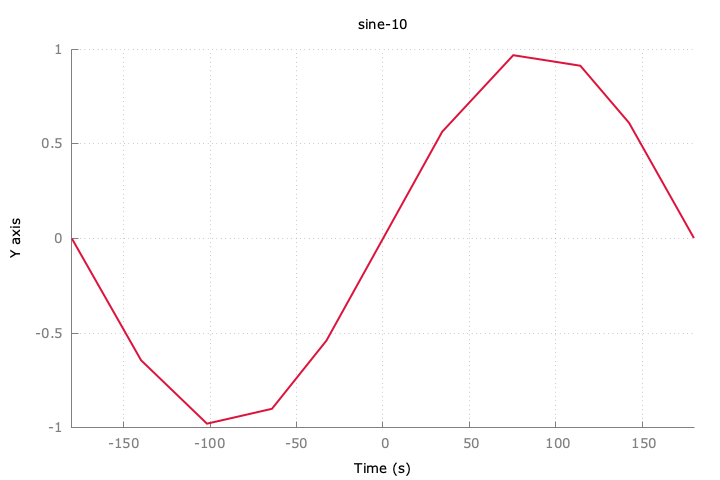
10件でも特徴は分かりそう。
