しばらく前に、LTTBをPL/PGSQLで実装したので、それを使って今日の日経平均の大暴落がどのようなグラフになるのか、やってみた。
元データはInvesting.comからお借りした、2014年8月1日から2024年8月5日までの2,476レコード。
#!/usr/bin/env python3.11
# data from https://jp.investing.com/indices/japan-ni225-historical-data
# builtin modules
import os
import sys
# third-party modules
import matplotlib.pyplot as plt
import pandas as pd
import psycopg as pg
from psycopg.rows import dict_row, namedtuple_row
from sqlalchemy import create_engine
from sqlalchemy.dialects.postgresql import TIMESTAMP, REAL
num_plots = int(sys.argv[1])
# load data to PostgreSQL
with open('日経平均株価 過去データ.csv') as f:
data = pd.read_csv(f).apply(lambda x: x.str.replace(',', ''))
data.insert(0, 'serial', range(len(data), 0, -1))
engine = create_engine(f"postgresql://{os.environ.get('USER')}@localhost:5432/postgres")
data.to_sql('nikkei', engine, if_exists='replace', index=False, dtype={'終値': REAL})
# plot the largest triangle three buckets by PL/pgSQL
with pg.connect(f"dbname=postgres user={os.environ.get('USER')}") as con:
with con.cursor(row_factory = namedtuple_row) as cur:
cur.execute(f'''
WITH selected_data AS (
SELECT array_agg(POINT(nk.serial, nk.終値)) AS data_array
FROM (SELECT * FROM nikkei ORDER BY 日付け) AS nk
)
SELECT * FROM largest_triangle_three_buckets(
(SELECT data_array FROM selected_data),
{num_plots}
);
''')
result = [p[1:-1].split(',') for p in cur.fetchone()[0]]
plt.plot(range(1, len(result)+1), [float(r[1]) for r in result])
plt.show()データポイントを、フル、2,000、1,500、1,000、500、250、120、60、20と減らしていく。
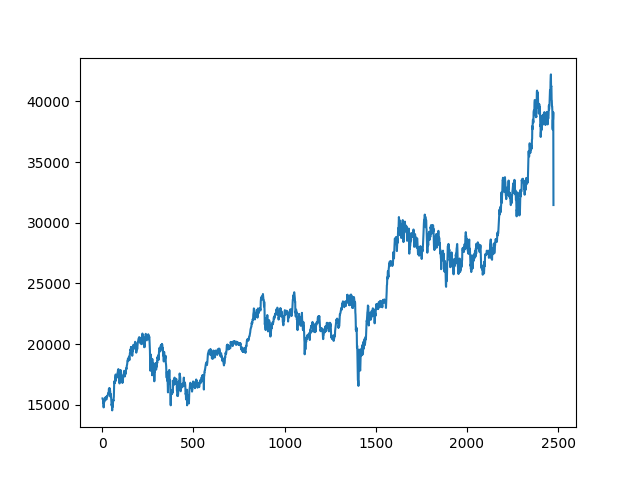
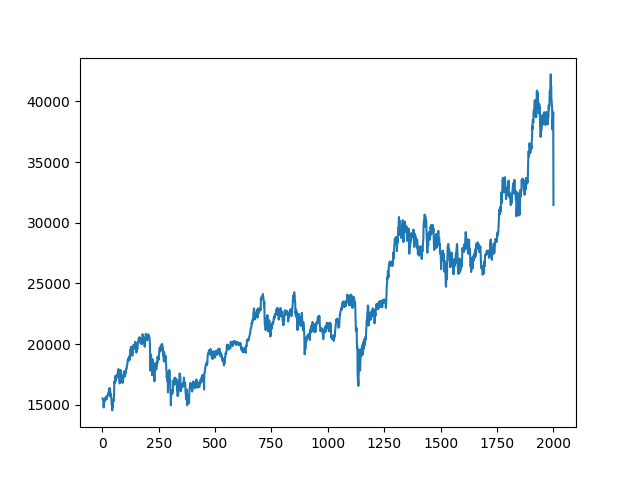
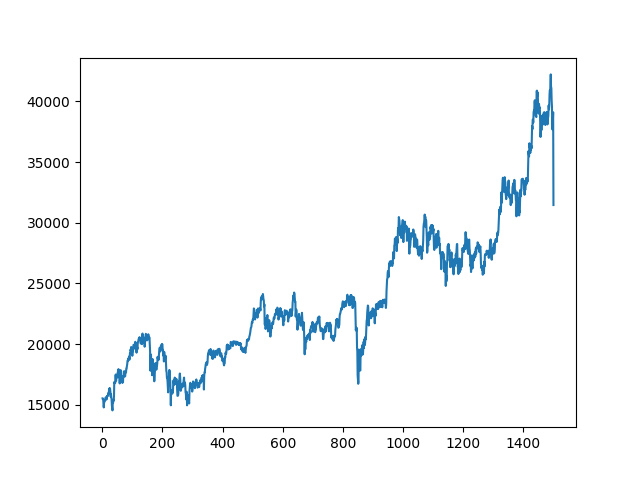
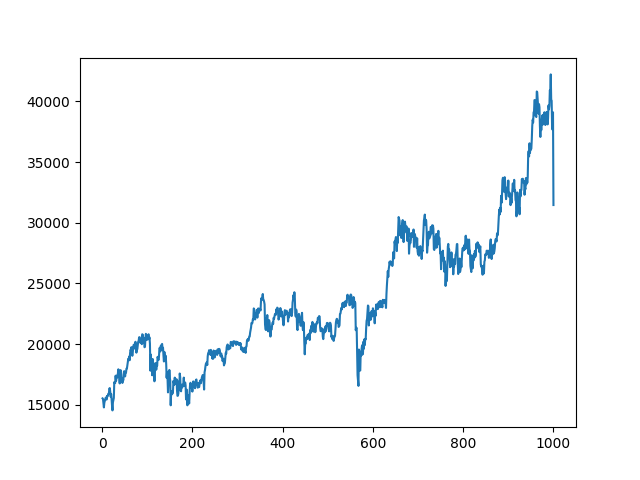
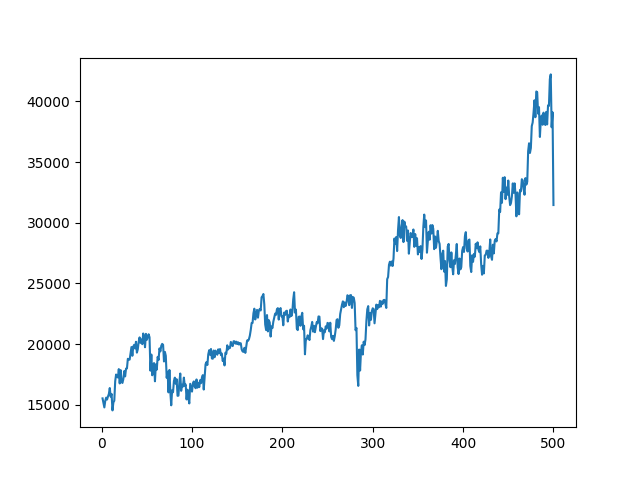
500データポイント、つまり約5分の1までは、今日の大暴落以外の動きについてもよく再現されている。
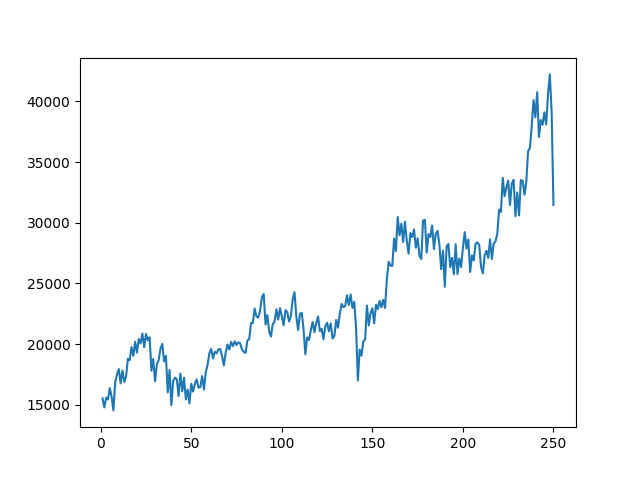
250まで落とすと、細かいところがあまり再現されなくなって来るが、実用上はあまり問題無さそう。
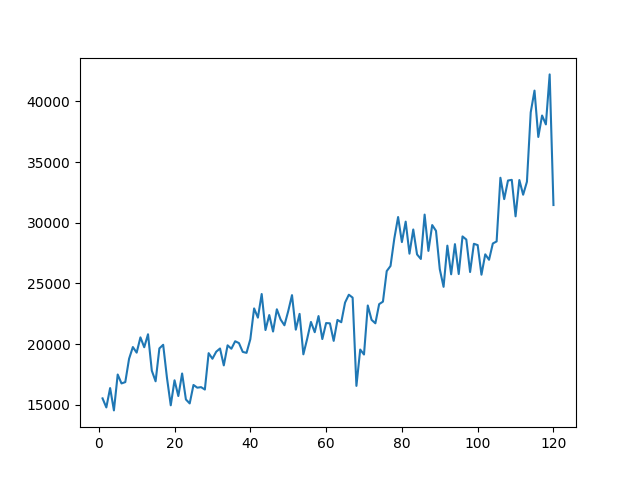
120だと、かなり省略されてしまう。
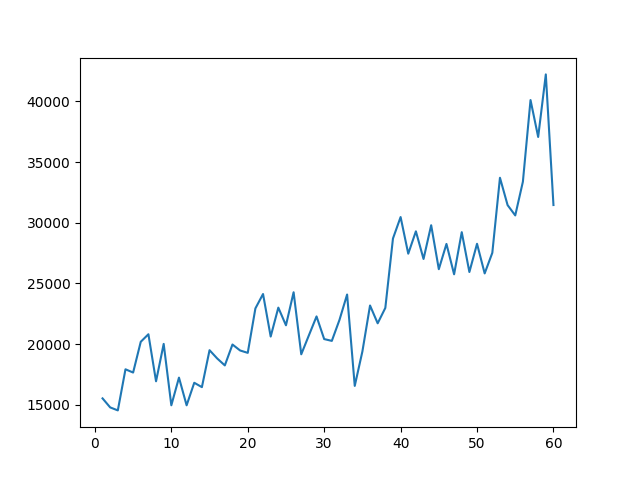
60だと、今日の大暴落が分かるが、
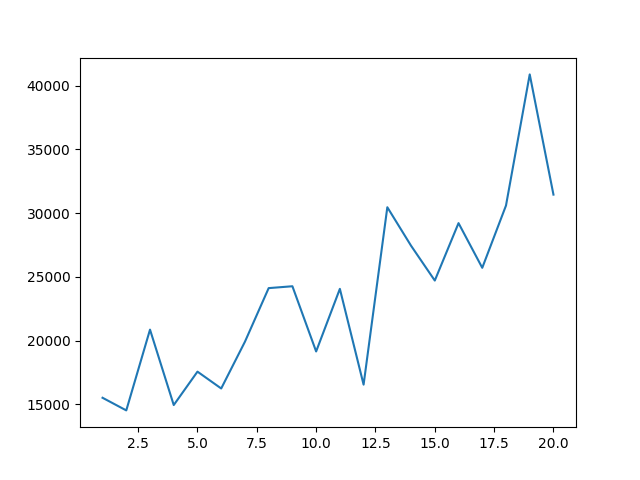
20までデータポイントを減らすと、あまり大暴落した感じには見えなくなる。