洪水浸水想定区域データをGoogleマップに載せたい
この数日試行錯誤していたんだけど、一番簡単な方法が分かったので、書いておく。
まず、国土交通省はオープンデータとして洪水浸水想定区域データを配布している。これは大きく2つ、国が管理する河川と都道府県が管理する河川に分かれており、さらに複数のデータ形式で配布している。これをベースにして各自治体は「水害ハザードマップ」なる印刷物を各家庭に配布していたり、ホームページにPDFとして掲載している、と。
この配布されているハザードマップ、あるいはPDFは、当然のことながら自治体の範囲で地図を作成するものだから、詳細な部分が分からない。具体的には、拙宅が水深何メートルの浸水を被りうるかが判断できない。
じゃあ、大元のオープンデータをダウンロードしてGoogleマップに重ね合わせれば良いじゃん、ということなんだけど、Googleマップを編集するマイマップでは、上記サイトから配布されているGML/Shapefile/GeoJSONのいずれも直接読み込めないので、何らかの変換が必要になると。試したところ、CSVなどでは中抜きの形状がポリゴンとして読み込めなかったりするので、GeoJSON → KMLが正解っぽい。
結論から言えば、GeoJSONに含まれるFeatureを1000件ごとに分割したGeoJSONファイルを作成し、geojson.ioでKMLに変換し、それをマイマップのレイヤーに追加すれば良い、と。
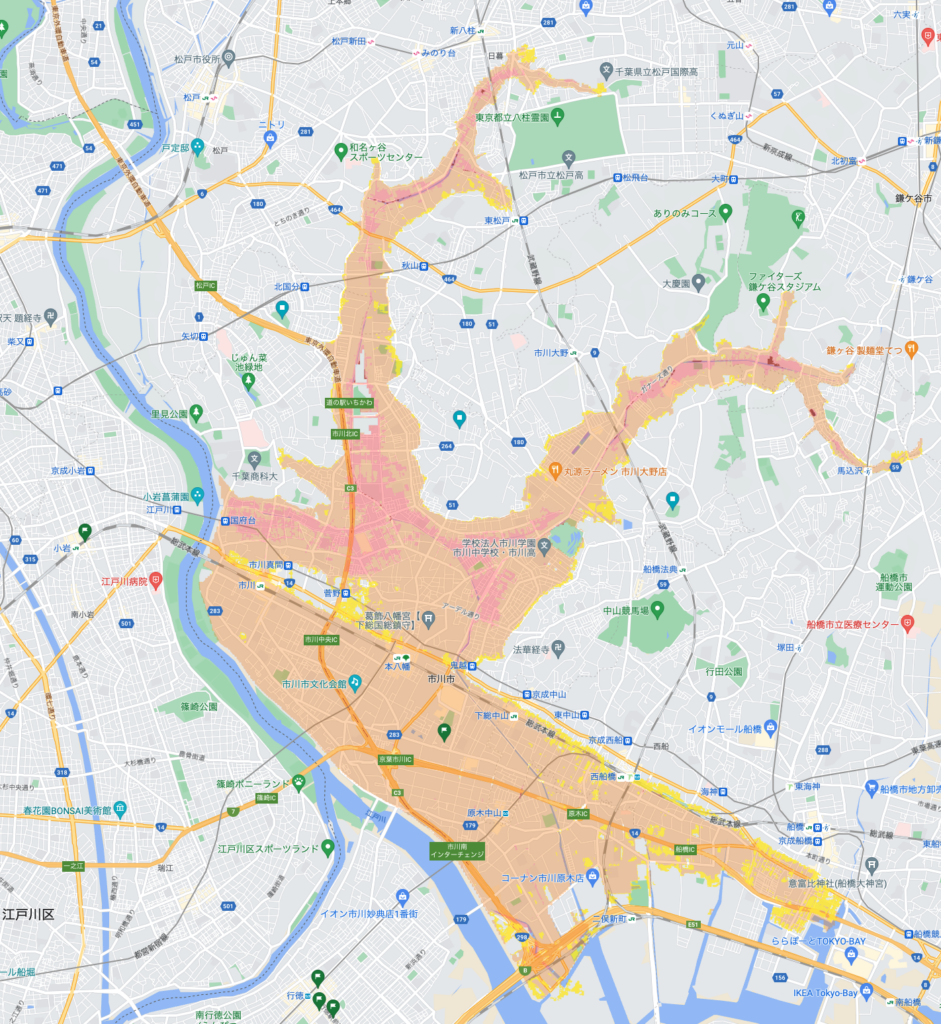
真間川の洪水浸水最大規模データを読み込んだのが下の例。
分割するにはPythonで、
import json
with open('source.geojson') as f:
df = json.load(f)
features = []
for feature in df['features']:
if 1 <= feature['id'] and feature['id'] < 1000:
features.apped(feature)
df['features'] = features
with open('0-1000.geojson', 'wt') as f:
json.dump(df, f, indent=2, ensure_ascii=False)みたいな感じで。
これをgeojson.ioで変換してみて、ダウンロードしたKMLが5MBを超えてるとマイマップが読み込んでくれないので、よしなに調整してほしい。上の真間川の例では、feature id=3490(一番広いオレンジ色の区域のポリゴン)のKMLだけで2.5MBにもなってしまうので、そこだけ抜き出して書き出すなどの工夫が必要だった。
まあ、GeoJSONはエディタで編集出来るので、featureが少ないGeoJSONならコードを書かなくても何とかなるっちゃなる。ただ、例えば江戸川だとGeoJSONが450MBとかになるので、エディタがお亡くなりますw
追記:江戸川のデータは少し古く、容量が大きいこともあってgeojson.ioで変換するのが面倒になり、下記のようなコードでKMLを書き出すことにした。"A31_201"というpropertyが浸水深ランクなので、extended dataとして追加するようにしている。
#!/usr/bin/python3
import json
import simplekml
def write_kml(df, fn):
kml = simplekml.Kml()
for feature in df['features']:
geom = feature['geometry']
geom_type = geom['type']
pl = kml.newpolygon(name=df['features'][0]['id'],
outerboundaryis=geom['coordinates'][0])
ex_data = simplekml.ExtendedData()
ex_data.newdata(name='A31_201', value=df['features'][0]['properties']['A31_201'])
pl.extendeddata = ex_data
kml.save(fn)
with open('A31-20-19_83-303-江戸川.geojson') as f:
df = json.load(f)
features = []
for feature in df['features']:
if feature['id'] % 2000 == 0:
buf = df
buf['features'] = features
write_kml(buf, '{:05d}.kml'.format(feature['id']))
features = []
else:
features.append(feature)
df['features'] = features
write_kml(df, '{:05d}.kml'.format(feature['id']))![ArcGIS Proではじめる地理空間データ分析 [ 桐村 喬 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/0330/9784772220330_1_4.jpg?_ex=128x128)