追記(2024.1028):最新版。
数日前からAzure Database for PostgreSQLでのApache AGEのプレビューが開始されたので、先に書いたエントリーと同じようなことをやってみる。
Azure Database for PostgreSQLを設定する
AzureポータルからAzure Database for PostgreSQLをデプロイする。デプロイが完了したら、[設定]→[サーバーパラメーター]と進み、
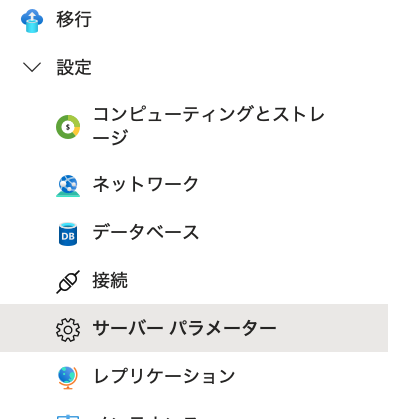
検索フィルタに”extension”を入力すると、[azure.extensions]が表示されるので、”AGE”にチェックを入れる。
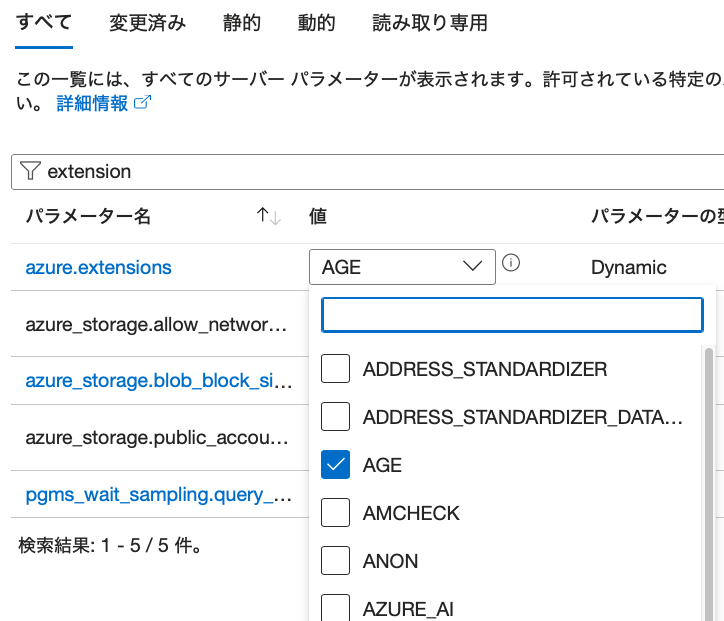
同様に、”shared_preload_libraries”でも、”AGE”にチェックを入れてから、保存する。
次に、同じく[設定]→[接続]と進み、psqlコマンドをコピーし、CloudShellあるいはローカルのターミナルから接続する。
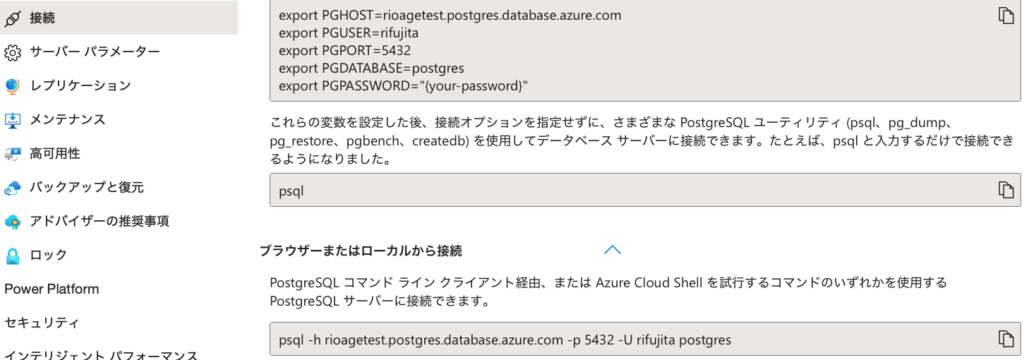
接続できたら、CREATE EXTENSIONを実行して、AGEを有効化する。
postgres=> CREATE EXTENSION IF NOT EXISTS age CASCADE;
CREATE EXTENSION以上でサーバ側の準備は完了。
データをダウンロードする
今回は、映画のタイトルと出演俳優のデータをグラフ化するので、kaggleのIMDB Films By Actor For 10K ActorsからCSVファイルをダウンロードする(要登録)。
Pythonコードを保存する
以下のPythonコードと、ダウンロードしたCSVファイルを同じディレクトリに置いて”-i”(初期化)オプションを付けて実行する。
#!/usr/bin/env python3.11
# -*- coding: utf-8 -*-
# builtin modules
import argparse
import json
import os
import sys
# third party modules
while True:
try:
import pandas as pd
break
except:
os.system(f"{sys.executable} -m pip install pandas")
while True:
try:
import psycopg as pg
from psycopg.rows import dict_row, namedtuple_row
break
except:
os.system(f"{sys.executable} -m pip install psycopg")
while True:
try:
from pyvis.network import Network
break
except ModuleNotFoundError:
os.system(f"{sys.executable} -m pip install pyvis")
# Constants
AG_GRAPH_NAME = "actorfilms"
# exit with redden message
def exit_with_error(msg) -> None:
sys.exit("\033[31m" + msg + "\033[0m")
# create graph database and add data
def createGraph(cur: pg.cursor) -> None:
print("Creating graph database...")
try:
cur.execute(f"SELECT * FROM ag_graph WHERE name='{AG_GRAPH_NAME}'")
except pg.errors.UndefinedTable:
exit_with_error("Failed to create graph database.\nPlease check if AGE extension is installed.")
row = cur.fetchone()
if row is not None:
cur.execute(f"SELECT drop_graph('{AG_GRAPH_NAME}', true)")
cur.execute(f"SELECT create_graph('{AG_GRAPH_NAME}')")
print("Adding Graph Data...")
# read csv file downloaded from https://www.kaggle.com/datasets/darinhawley/imdb-films-by-actor-for-10k-actors
df = pd.read_csv("actorfilms.csv", usecols = ["Actor", "ActorID", "Film"])
df["Actor"] = df["Actor"].str.replace("'", r"\'")
df["Film"] = df["Film"].str.replace("'", r"\'")
ln = len(df)
row_num = 1
queries = []
saved_actor = ''
for row in df.itertuples():
# the file is sorted by actor, so we can avoid creating the same actor multiple times
if row.Actor == saved_actor:
queries.append(f"""
SELECT * FROM cypher('{AG_GRAPH_NAME}', $$ MERGE (m:Film {{title: '{row.Film}'}}) $$) AS (a agtype);
SELECT * FROM cypher('{AG_GRAPH_NAME}', $$ MATCH (n:Actor {{name: '{row.Actor}'}}), (m:Film {{title: '{row.Film}'}}) CREATE (n)-[:ACTED_IN]->(m) $$) AS (a agtype);
""")
else:
queries.append(f"""
SELECT * FROM cypher('{AG_GRAPH_NAME}', $$ CREATE (n:Actor {{name: '{row.Actor}'}}) $$) AS (a agtype);
SELECT * FROM cypher('{AG_GRAPH_NAME}', $$ MERGE (m:Film {{title: '{row.Film}'}}) $$) AS (a agtype);
SELECT * FROM cypher('{AG_GRAPH_NAME}', $$ MATCH (n:Actor {{name: '{row.Actor}'}}), (m:Film {{title: '{row.Film}'}}) CREATE (n)-[:ACTED_IN]->(m) $$) AS (a agtype);
""")
saved_actor = row.Actor
# create nodes and edges in batches of 1000
if row_num % 1000 == 0:
print(f"Adding data {row_num}/{ln}...")
cur.execute(''.join(queries))
queries = []
row_num += 1
if len(queries) > 0:
print(f"Adding data {row_num}/{ln}...")
cur.execute(''.join(queries))
# show graph
def showGraph(cur: pg.cursor, limit: int, film: str, actor: str) -> None:
if actor is not None and actor != '':
wk_actor = f" {{name: '{actor}'}}"
else:
wk_actor = ''
if film is not None and film != '':
wk_film = f" {{title: '{film}'}}"
else:
wk_film = ''
query = f"""
SELECT *
FROM cypher('{AG_GRAPH_NAME}', $$
MATCH (n:Actor{wk_actor})-[r:ACTED_IN]->(m:Film{wk_film})
RETURN n,r,m
LIMIT {limit}
$$) AS (n agtype, r agtype, m agtype);
"""
cur.execute(query)
rows = cur.fetchall()
if len(rows) == 0:
exit_with_error("No records found.")
net = Network(height = "1600px", width = "100%")
for row in rows:
temp_v = [json.loads(row.n[:-len("::vertex")]), json.loads(row.m[:-len("::vertex")])]
temp_e = json.loads(row.r[:-len("::edge")])
for v in temp_v:
if v["label"] == "Actor":
color = "#F79667"
net.add_node(v["id"], label = v["properties"]["name"], color = color)
elif v["label"] == "Film":
color = "#57C7E3"
net.add_node(v["id"], label = v["properties"]["title"], color = color)
else:
color = "blue"
net.add_edge(temp_v[0]["id"], temp_v[1]["id"], label = temp_e["label"])
net.toggle_physics(True)
net.show(f"{AG_GRAPH_NAME}.html", notebook = False)
# open the browser if the platform is macOS
if sys.platform == "darwin":
os.system(f"open {AG_GRAPH_NAME}.html")
def main() -> None:
# pass initdb to create the graph database
parser = argparse.ArgumentParser(description = "IMDB Graph")
parser.add_argument("--initdb", "-i", action = 'store_true', help = "Initialize the database if specified")
parser.add_argument("--limit", "-l", type = int, default = 1000, help = "Number of records to display in the graph")
parser.add_argument("--film", "-f", default = '', help = "Film to search for")
parser.add_argument("--actor", "-a", default = '', help = "Actor to search for")
args = parser.parse_args()
try:
con = pg.connect(
host = "your_server.postgres.database.azure.com",
port = 5432,
dbname = "postgres",
user = "your_account",
password = "your_password",
options = "-c search_path=ag_catalog,'$user',public"
)
except:
exit_with_error("Failed to connect to the database.")
cur = con.cursor(row_factory = namedtuple_row)
# Run once to create the graph database
if args.initdb:
createGraph(cur)
# Show the graph
showGraph(cur, args.limit, args.film, args.actor)
cur.close()
con.close()
if __name__ == "__main__":
main()
con = pg.connect()のパラメータはAzureポータルの[接続]を見ながら、適宜修正する。
- cypherでCREATEではなくMERGEを使う理由は以前に書いた通り。
- psycopgは自動的にprepared statementにしてくれるが、データ毎行でcur.execute()すると大変遅い。このコードではデータ1,000行に対応するクエリーをまとめて実行するようにしている。
- より高速にするにはcypherを使わず、直接PostgreSQLのテーブルを操作する方法もあるが、邪道なのでここでは触れない。
- コードのコメントに記載した通り、age.soの初回ロード時にエラーが発生する問題があり、showGraph()銭湯のtry-except-passでエラーを握りつぶすには、autocommitをTrueに設定する=トランザクションにしない必要がある。データの初回ロード時には既にage.soはロードされているのでshowGraph()は問題なく実行される。
- より大量のデータを投入するのであれば、asyncにするなりマルチスレッドにするなり、工夫をする必要がある。
コードを実行する
で、実行。結構時間がかかるので、しばらく放置しておくと良い。
% chmod 755 imdb-graph.py
% time ./imdb-graph.py -i
Creating graph database...
Adding Graph Data...
Adding data 1/191873...
Adding data 2/191873...
Adding data 3/191873...
......
./imdb-graph.py -i 8.07s user 2.02s system 0% cpu 37:21.04 total
データ投入が完了すれば、そのままhtmlを出力するので、ブラウザで開く(macOSの場合、自動的にブラウザが起動する)。
初回ロード時に生成されるグラフは以下のようになる。actorfilms.html

初回のロード後、以下のようにスクリプトを実行すると、
./imdb-graph.py -f 'Keanu Reeves'このようなグラフが得られる。actorfilms_Keanu.html
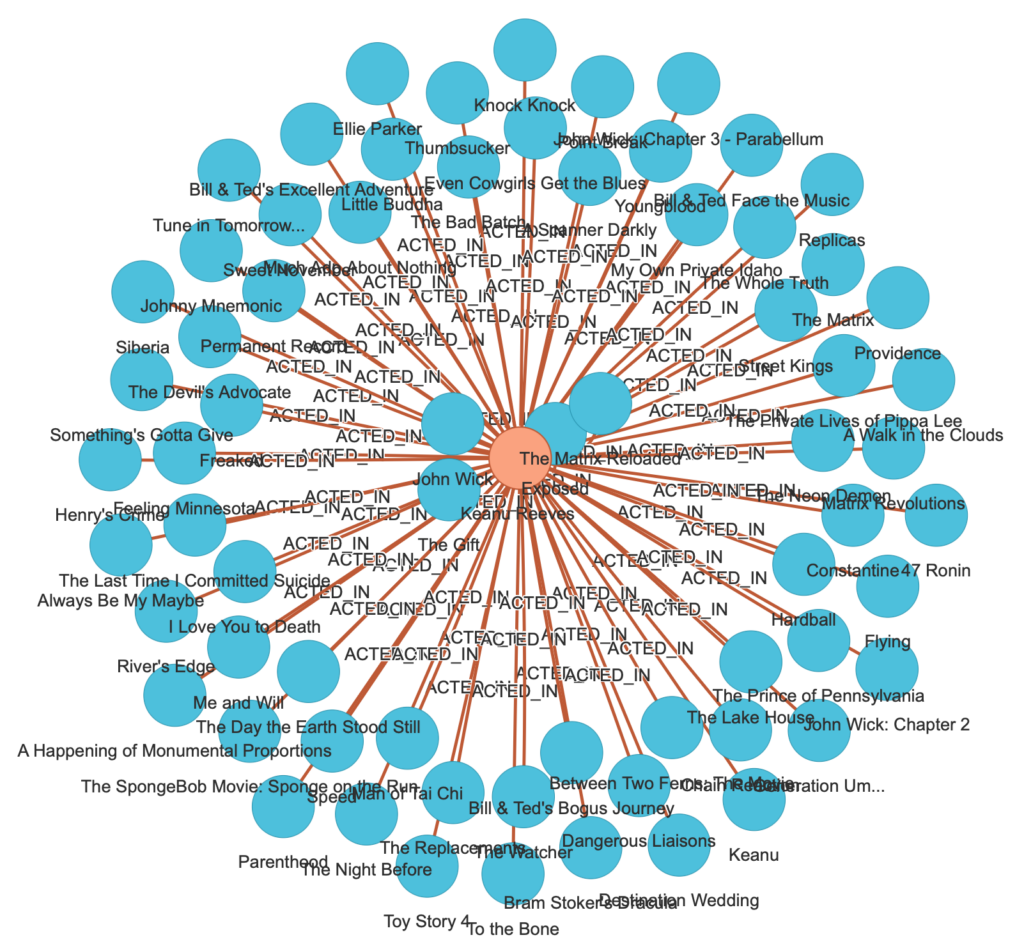
より高度なクエリーは、Apache AGEのドキュメントが参考になる。
注:性能向上のためにインデックスを操作できないか調べてみたが、どうやらデフォルトで張られている様子。
postgres=# \d+ ag_label
テーブル"ag_catalog.ag_label"
列 | タイプ | 照合順序 | Null 値を許容 | デフォルト | ストレージ | 圧縮 | 統計目標 | 説明
----------+------------+----------+---------------+------------+------------+------+----------+------
name | name | | not null | | plain | | |
graph | oid | | not null | | plain | | |
id | label_id | | | | plain | | |
kind | label_kind | | | | plain | | |
relation | regclass | | not null | | plain | | |
seq_name | name | | not null | | plain | | |
インデックス:
"ag_label_graph_oid_index" UNIQUE, btree (graph, id)
"ag_label_name_graph_index" UNIQUE, btree (name, graph)
"ag_label_relation_index" UNIQUE, btree (relation)
"ag_label_seq_name_graph_index" UNIQUE, btree (seq_name, graph)
外部キー制約:
"fk_graph_oid" FOREIGN KEY (graph) REFERENCES ag_graph(graphid)
アクセスメソッド: heap追記(2024.10.27):上のインデックスはMATCHに対して有効では無かった。少し書き直してみた。