- Azure Database for PostgreSQLでApache AGEを試してみる
- 少し書き直してみた(6.4倍ぐらい速くなった)
- Azure Database for PostgreSQL + Apache AGEのインデックス
上記エントリーをまとめて、書き直したコードが以下。
#!/usr/bin/env python3.11
# -*- coding: utf-8 -*-
# builtin modules
import argparse
import json
import os
import resource
import sys
import threading
import time
# third party modules
while True:
try:
import pandas as pd
break
except:
os.system(f"{sys.executable} -m pip install pandas")
while True:
try:
import psycopg as pg
from psycopg.rows import dict_row, namedtuple_row
break
except:
os.system(f"{sys.executable} -m pip install psycopg")
while True:
try:
import psycopg_pool
break
except:
os.system(f"{sys.executable} -m pip install psycopg-pool")
while True:
try:
from pyvis.network import Network
break
except ModuleNotFoundError:
os.system(f"{sys.executable} -m pip install pyvis")
# Constants
AG_GRAPH_NAME = "actorfilms"
# Global Variables
connection_string = """
host=your_server.postgres.database.azure.com
port=5432
dbname=postgres
user=your_account
password=admin_password
options='-c search_path=ag_catalog,\"$user\",public'
"""
# See, https://docs.python.org/ja/3/library/resource.html
resource.setrlimit(resource.RLIMIT_NOFILE, (8192, 9223372036854775807))
# See, https://learn.microsoft.com/en-us/azure/postgresql/flexible-server/concepts-limits
# If number of connections exceeds 8192, you will get the error.
pg_pool = psycopg_pool.ConnectionPool(connection_string, max_size = 1703, min_size = 128)
# exit with redden message
def exit_with_error(msg) -> None:
sys.exit("\033[31m" + msg + "\033[0m")
# initialize graph database
def initGraph() -> None:
print("Creating graph database...")
with pg_pool.connection() as conn:
with conn.cursor() as cur:
try:
cur.execute(f"SELECT * FROM ag_graph WHERE name='{AG_GRAPH_NAME}'")
except pg.errors.UndefinedTable:
exit_with_error("Failed to create graph database.\nPlease check if AGE extension is installed.")
row = cur.fetchone()
if row is not None:
cur.execute(f"SELECT drop_graph('{AG_GRAPH_NAME}', true)")
cur.execute(f"SELECT create_graph('{AG_GRAPH_NAME}')")
# create all vertices at once
def createVertices(df: pd.DataFrame) -> None:
with pg_pool.connection() as conn:
with conn.cursor() as cur:
df["Actor"] = df["Actor"].str.replace("'", r"\'")
df["Film"] = df["Film"].str.replace("'", r"\'")
actors = df["Actor"].unique()
films = df["Film"].unique()
print(f"Creating {len(actors)} vertices...")
cur.execute(''.join([f"SELECT * FROM cypher('{AG_GRAPH_NAME}', $$ CREATE (n:Actor {{name: '{actor}'}}) $$) AS (a agtype);" for actor in actors]))
print(f"Creating {len(films)} vertices...")
cur.execute(''.join([f"SELECT * FROM cypher('{AG_GRAPH_NAME}', $$ CREATE (m:Film {{title: '{film}'}}) $$) AS (a agtype);" for film in films]))
print("Creating indices...")
cur.execute(f'CREATE INDEX ON {AG_GRAPH_NAME}."Actor" USING GIN (properties);')
cur.execute(f'CREATE INDEX ON {AG_GRAPH_NAME}."Actor" (id);')
cur.execute(f'CREATE INDEX ON {AG_GRAPH_NAME}."Film" USING GIN (properties);')
cur.execute(f'CREATE INDEX ON {AG_GRAPH_NAME}."Film" (id);')
# create edges
def createEdges(df: pd.DataFrame) -> None:
print("Creating edges...")
threads = []
threadId = 1
ln = len(df)
row_num = 1
films = []
saved_actor = df["Actor"][0]
for row in df.itertuples():
if row.Actor == saved_actor:
films.append(row.Film)
else:
t = threading.Thread(target = createEdgesPerActor, args = (saved_actor, films, row_num, ln, threadId))
t.start()
threads.append(t)
threadId += 1
saved_actor = row.Actor
films = [row.Film]
row_num += 1
if len(films) > 0:
t = threading.Thread(target = createEdgesPerActor, args = (saved_actor, films, row_num, ln, threadId))
t.start()
threads.append(t)
for i in threads:
i.join()
with pg_pool.connection() as conn:
with conn.cursor() as cur:
# added 2024.10.28
cur.execute(f'CREATE INDEX ON {AG_GRAPH_NAME}."ACTED_IN" (start_id);')
cur.execute(f'CREATE INDEX ON {AG_GRAPH_NAME}."ACTED_IN" (end_id);')
cur.execute("COMMIT;")
# create edges
def createEdgesPerActor(actor: str, films: tuple, row_num: int, ln: int, threadId: int) -> None:
query_films = ', '.join([f"(m{idx}:Film {{title: '{film}'}})" for idx, film in enumerate(films)])
query_rels = ', '.join([f"(n)-[:ACTED_IN]->(m{idx})" for idx, _ in enumerate(films)])
query = f"SELECT * FROM cypher('{AG_GRAPH_NAME}', $$ MATCH (n:Actor {{name: '{actor}'}}), {query_films} CREATE {query_rels} $$) AS (a agtype);"
while True:
try:
with pg_pool.connection() as conn:
with conn.cursor() as cur:
cur.execute(query)
break
except:
pass
print(f"{len(films)} films for '{actor}' created, {row_num} / {ln} processed by thread {threadId}.{' '*10}", end = '\r')
# show graph
def showGraph(limit: int, film: str, actor: str) -> None:
if actor is not None and actor != '':
wk_actor = f" {{name: '{actor}'}}"
else:
wk_actor = ''
if film is not None and film != '':
wk_film = f" {{title: '{film}'}}"
else:
wk_film = ''
query = f"""
SELECT *
FROM cypher('{AG_GRAPH_NAME}', $$
MATCH (n:Actor{wk_actor})-[r:ACTED_IN]->(m:Film{wk_film})
RETURN n,r,m
LIMIT {limit}
$$) AS (n agtype, r agtype, m agtype);
"""
with pg_pool.connection() as conn:
with conn.cursor(row_factory = namedtuple_row) as cur:
cur.execute(query)
rows = cur.fetchall()
if len(rows) == 0:
exit_with_error("No records found.")
net = Network(height = "1600px", width = "100%")
for row in rows:
temp_v = [json.loads(row.n[:-len("::vertex")]), json.loads(row.m[:-len("::vertex")])]
temp_e = json.loads(row.r[:-len("::edge")])
for v in temp_v:
if v["label"] == "Actor":
color = "#F79667"
net.add_node(v["id"], label = v["properties"]["name"], color = color)
elif v["label"] == "Film":
color = "#57C7E3"
net.add_node(v["id"], label = v["properties"]["title"], color = color)
else:
color = "blue"
net.add_edge(temp_v[0]["id"], temp_v[1]["id"], label = temp_e["label"])
net.toggle_physics(True)
net.show(f"{AG_GRAPH_NAME}.html", notebook = False)
# open the browser if the platform is macOS
if sys.platform == "darwin":
os.system(f"open {AG_GRAPH_NAME}.html")
def main() -> None:
# pass initdb to create the graph database
parser = argparse.ArgumentParser(description = "IMDB Graph")
parser.add_argument("--initdb", "-i", action = 'store_true', help = "Initialize the database if specified")
parser.add_argument("--limit", "-l", type = int, default = 1000, help = "Number of records to display in the graph")
parser.add_argument("--film", "-f", default = '', help = "Film to search for")
parser.add_argument("--actor", "-a", default = '', help = "Actor to search for")
args = parser.parse_args()
pg_pool.open()
pg_pool.wait(timeout = 30.0)
# Run once to create the graph database
if args.initdb:
# read csv file downloaded from https://www.kaggle.com/datasets/darinhawley/imdb-films-by-actor-for-10k-actors
df = pd.read_csv(f"{AG_GRAPH_NAME}.csv", usecols = ["Actor", "ActorID", "Film"])
initGraph()
createVertices(df)
createEdges(df)
# Show the graph
showGraph(args.limit, args.film, args.actor)
pg_pool.close()
if __name__ == "__main__":
main()
./imdb-graph.py -i 14.87s user 27.34s system 25% cpu 2:44.01 total最初は、cpu 37:21.04 totalだったのがcpu 2:44.01 totalなので、13.7倍ぐらい速くなった。
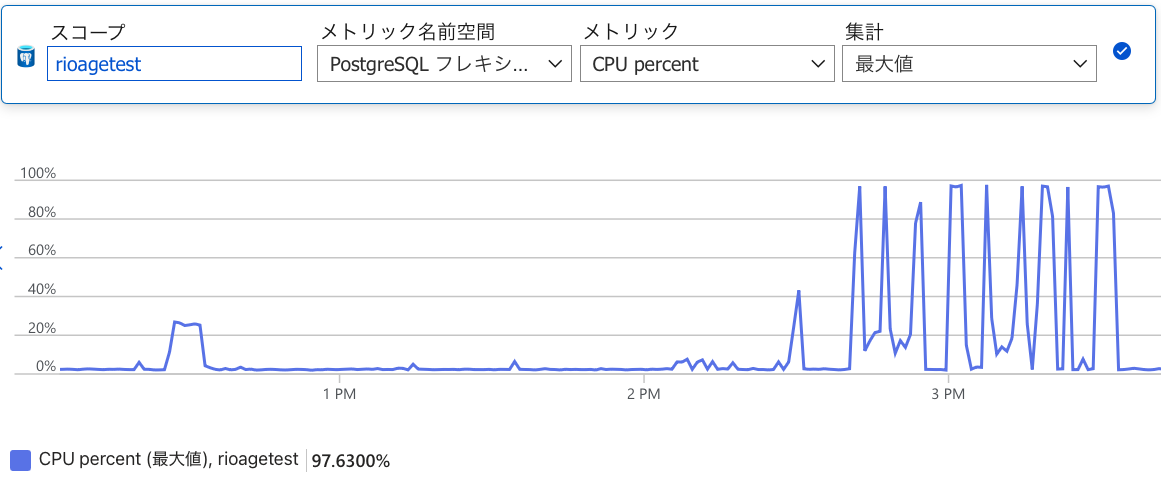
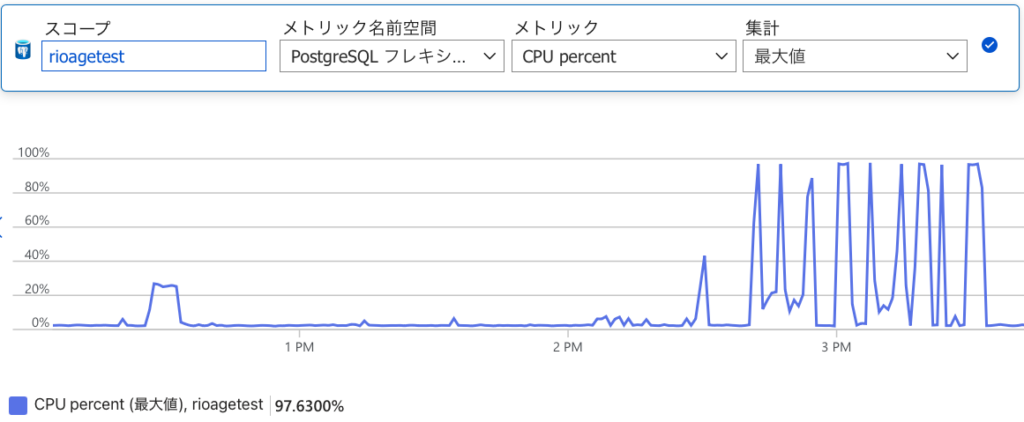
マルチスレッド化の前はサーバ側のCPUは最大でも25%ぐらいしか使えていなかったが(下のグラフの12:30頃のピーク)、これで使い切れるようになったのでこれ以上はスケールアップしないと無理なはず。
改修ポイントは以下。
- 56〜60行:クライアントであるmacOSのファイルデスクリプタの上限を上げて、コネクションプールで張る接続数の上限までコネクションを生成できるようにした。
- 95〜99行:Actor / FilmのpropertiesにGIN(汎用転置)インデックスを、idにb-treeインデックスを張るようにした。MATCH (n:Actor {name: ‘actor_name’}), (m:Film {title: ‘film_title’}) CREATE (n)-[:ACTED_IN]->(m)というcypherクエリでpropertiesのSeqScan(nameを探す)とCREATEする際のidのSeqScan(start_idとend_idを探す)を避けるため。
- 115〜117行:threadingで、Actor毎のFilmへのedgeを並列に投入するようにした。139行のcreateEdgesPerActor()が本体。
- 133〜136行:ACTED_INのstart_id / end_idにb-treeインデックスを張るようにした。これは後の検索処理でSeqScanを避けるため。
- 143〜148行:56行で用意したコネクションプールを利用して、並列にedgeを投入する。
- 211〜212行:pool.open()と、poolのmin_sizeになるまでpool.wait()する。
