GraphRAGの一歩手前、Knowledge Graphを作るところまで、この辺を参考にやってみた。生成されたhtmlをアップしておいた。Apache AGEで実装できるかを試すのが目的なので、GraphRAGの説明は無し。適宜検索して欲しい。
さて。langchain_community.graphs.age_graphにAGEGraphというのがあるが、これがいまいち動いてくれないので、そのコードを参照しつつ実装したら以下のようになった。参考にしたNotebookで使われているNeo4Jなら特に問題なく動くと思われるが、現時点ではApache AGEを使う場合、泥臭くコードを書いていかないと動かない、といったところ。それほど難易度は高くない。
#!/usr/bin/env python3.11
# built-in modules
import json
import os
import pathlib
import pickle
import re
import sys
from typing import Any, Dict, Tuple, List, Optional, Union
cur_python = f"python{sys.version_info[0]}.{sys.version_info[1]}"
# third-party modules
try:
from langchain.chains import GraphCypherQAChain
from langchain.text_splitter import TokenTextSplitter
except ModuleNotFoundError:
os.system(f'{cur_python} -m pip install langchain')
from langchain.chains import GraphCypherQAChain
from langchain.text_splitter import TokenTextSplitter
try:
from langchain_community.document_loaders import WikipediaLoader
from langchain_community.graphs.graph_document import GraphDocument
except ModuleNotFoundError:
os.system(f'{cur_python} -m pip install langchain_community')
from langchain_community.document_loaders import WikipediaLoader
from langchain_community.graphs.graph_document import GraphDocument
try:
from langchain_experimental.graph_transformers import LLMGraphTransformer
except ModuleNotFoundError:
os.system(f'{cur_python} -m pip install langchain_experimental')
from langchain_experimental.graph_transformers import LLMGraphTransformer
try:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
except ModuleNotFoundError:
os.system(f'{cur_python} -m pip install langchain_openai')
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
try:
import psycopg as pg
from psycopg.rows import dict_row, namedtuple_row
except ModuleNotFoundError:
os.system(f'{cur_python} -m pip install psycopg')
import psycopg as pg
from psycopg.rows import dict_row, namedtuple_row
try:
from pyvis.network import Network
except ModuleNotFoundError:
os.system(f'{cur_python} -m pip install pyvis')
from pyvis.network import Network
# global variables
ag_graph_name = "graphrag"
graph_docs_path = pathlib.Path("graph_docs.pkl")
def load_documents():
# Read the wikipedia article
raw_documents = WikipediaLoader(query="Elizabeth I").load()
# Define chunking strategy
text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)
documents = text_splitter.split_documents(raw_documents[:3])
return documents
def convert_to_graph_documents(documents):
# Convert the documents to graph documents
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-0125")
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(documents)
return graph_documents
def format_properties(properties: Dict[str, Any], id: Union[str, None] = None) -> str:
props = []
# wrap property key in backticks to escape
for k, v in properties.items():
prop = f"`{k}`: {json.dumps(v)}"
props.append(prop)
if id is not None and "id" not in properties:
props.append(
f"id: {json.dumps(id)}" if isinstance(id, str) else f"id: {id}"
)
return "{" + ", ".join(props) + "}"
def clean_graph_labels(label: str) -> str:
return re.sub("[^0-9a-zA-Z]+", "_", label)
def add_graph_documents(cur: pg.cursor, graph_documents: List[GraphDocument], include_source: bool = False) -> None:
# query for inserting nodes
node_insert_query = "MERGE (n:`{label}` {properties})"
if include_source == True:
node_insert_query += " MERGE (d:Document {d_properties}) MERGE (d)-[:MENTIONS]->(n)"
# query for inserting edges
edge_insert_query = """
MERGE (from:`{f_label}` {f_properties})
MERGE (to:`{t_label}` {t_properties})
MERGE (from)-[:`{r_label}` {r_properties}]->(to)
"""
for doc in graph_documents:
# if we are adding sources, create an id for the source
if include_source == True:
if not doc.source.metadata.get("id"):
doc.source.metadata["id"] = md5(
doc.source.page_content.encode("utf-8")
).hexdigest()
# insert entity nodes
for node in doc.nodes:
node.properties["id"] = node.id
if include_source:
query = node_insert_query.format(
label = node.type,
properties = format_properties(node.properties),
d_properties = format_properties(doc.source.metadata),
)
else:
query = node_insert_query.format(
label = clean_graph_labels(node.type),
properties = format_properties(node.properties),
)
cur.execute(f"SELECT * FROM cypher('{ag_graph_name}', $$ {query} $$) AS (n agtype)")
# insert relationships
for edge in doc.relationships:
edge.source.properties["id"] = edge.source.id
edge.target.properties["id"] = edge.target.id
inputs = {
"f_label": clean_graph_labels(edge.source.type),
"f_properties": format_properties(edge.source.properties),
"t_label": clean_graph_labels(edge.target.type),
"t_properties": format_properties(edge.target.properties),
"r_label": clean_graph_labels(edge.type).upper(),
"r_properties": format_properties(edge.properties),
}
query = edge_insert_query.format(**inputs)
cur.execute(f"SELECT * FROM cypher('{ag_graph_name}', $$ {query} $$) AS (n agtype)")
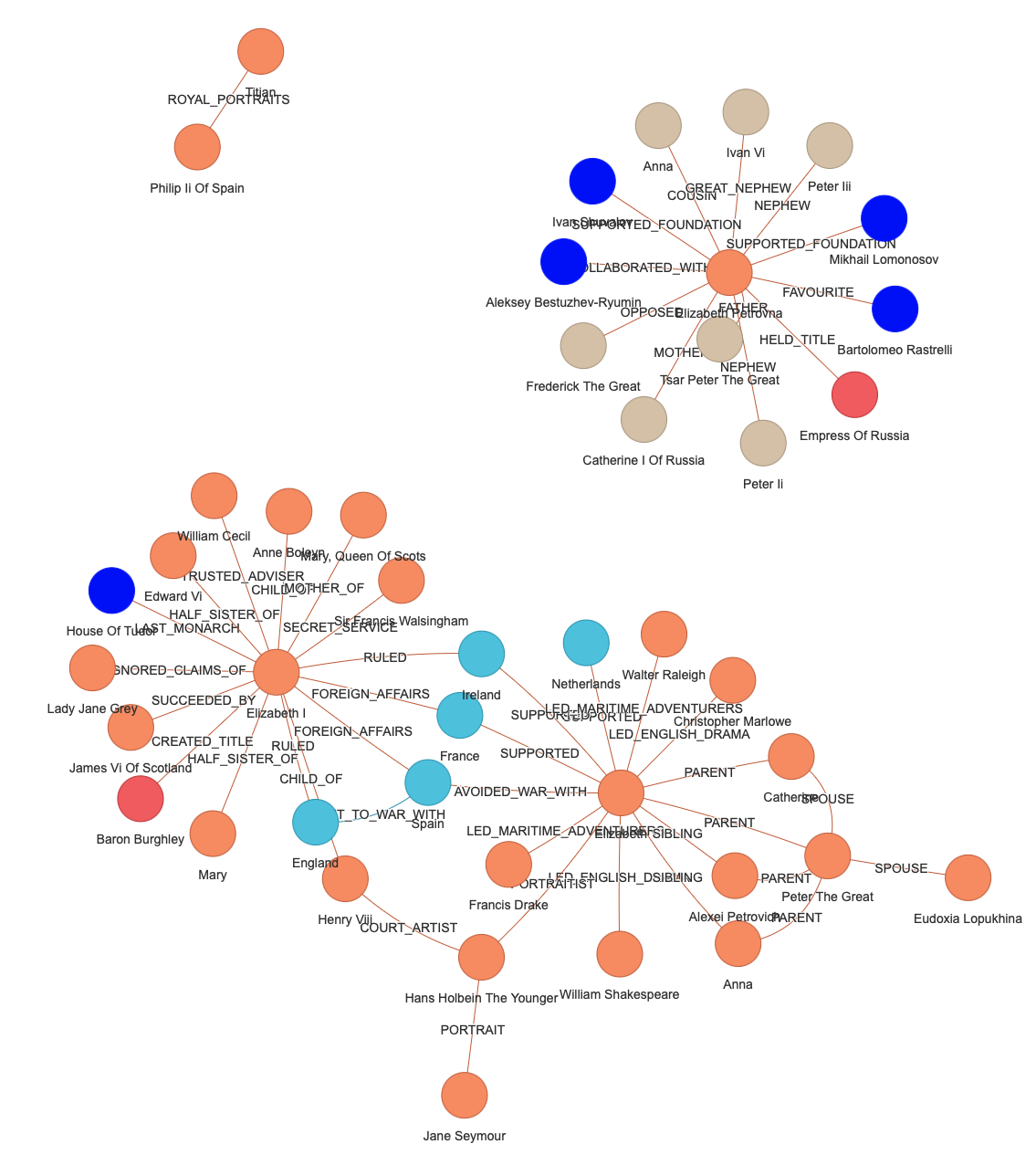
def showGraph(cur: pg.cursor):
# '!MENTIONS' expression in the original code doesn't work with AGE
# MATCH (s)-[r:!MENTIONS]->(t)
cur.execute(f"""
SELECT *
FROM cypher ('{ag_graph_name}', $$
MATCH (s)-[r]->(t)
RETURN s,r,t
LIMIT 50
$$) AS (s agtype, r agtype, t agtype)
""")
rows = cur.fetchall()
net = Network(height="1600px", width="100%")
for row in rows:
temp_v = [json.loads(row.s[:-len("::vertex")]), json.loads(row.t[:-len("::vertex")])]
temp_e = json.loads(row.r[:-len("::edge")])
for v in temp_v:
if v["label"] == "Person":
color = "#F79667"
elif v["label"] == "Country":
color = "#57C7E3"
elif v["label"] == "Monarch":
color = "#D9C8AE"
elif v["label"] == "Title":
color = "#F16767"
else:
color = "blue"
print(v)
net.add_node(v["id"], label=v["properties"]["id"], color=color)
net.add_edge(temp_v[0]["id"], temp_v[1]["id"], label=temp_e["label"])
net.toggle_physics(True)
net.show("graphrag.html", notebook=False, )
os.system('open graphrag.html')
def main() -> None:
print("Loading documents...")
if graph_docs_path.exists() == False:
docs = load_documents()
print("Converting documents to graph documents...")
graph_docs = convert_to_graph_documents(docs)
with graph_docs_path.open(mode = "wb") as f:
pickle.dump(graph_docs, f)
else:
with graph_docs_path.open(mode = "rb") as f:
graph_docs = pickle.load(f)
with pg.connect(
host="localhost",
port=5455,
dbname="postgres",
user=os.environ.get('USER'),
password="passw0rd",
options="-c search_path=ag_catalog,'$user',public"
) as conn:
with conn.cursor(row_factory = namedtuple_row) as cur:
print("Creating graph database...")
cur.execute(f"SELECT * FROM ag_graph WHERE name='{ag_graph_name}'")
row = cur.fetchone()
if row is not None:
cur.execute(f"SELECT drop_graph('{ag_graph_name}', true)")
cur.execute(f"SELECT create_graph('{ag_graph_name}')")
print("Adding graph documents to AGE...")
add_graph_documents(cur, graph_docs)
with conn.cursor(row_factory = namedtuple_row) as cur:
print("Showing graph...")
showGraph(cur)
if __name__ == "__main__":
main()処理の大まかな流れは以下。
- 182〜190行:OpenAIのAPIを毎回叩くと料金が辛いので、グラフドキュメントを一度生成したら、Pickleでシリアライズしておく。デバッグ中に、1回$0.01でも何度も叩くうちにアカンってなったw
- 61行・load_documents():Wikipediaから取ってきたドキュメントをチャンキングして返すだけ。
- 71行・convert_to_graph_documents():OpenAIのAPIでLLMを取得して、ドキュメントをグラフドキュメントにする。中身は以下のようになっているので、自前でパースしても大したことはない。
[
GraphDocument(
nodes=[
Node(id='Elizabeth I', type='Person'),
Node(id='England', type='Country'),
Node(id='Ireland', type='Country'),
......
],
relationships=[
Relationship(source=Node(id='Elizabeth I', type='Person'), target=Node(id='England', type='Country'), type='RULER'),
Relationship(source=Node(id='Elizabeth I', type='Person'), target=Node(id='Ireland', type='Country'), type='RULER'),
Relationship(source=Node(id='Elizabeth I', type='Person'), target=Node(id='House Of Tudor', type='Royal family'), type='MEMBER'),
......
],
source=Document(
metadata={
'title': 'Elizabeth I',
'summary': 'Elizabeth I (7 September 1533 – 24 March 1603) was Queen of ......
'source': 'https://en.wikipedia.org/wiki/Elizabeth_I'
},
page_content='Elizabeth I (7 September 1533 – 24 March 1603) was Queen .....
......- 192〜208行:グラフドキュメントをApache AGEを有効にしたPostgreSQLに投入する。
- 98行・add_graph_documents():本来は、langchain_community.graphs.age_graph.AGEGraphで出来るはずだが、現時点では色々な問題があることが分かったので、自前で。要はCypherでVertexとEdgeを投入しているだけ。
- 146行・showGraph():上で投入したグラフを50件だけ取得して、pyvisのネットワークに変換して表示している。先日書いたJaalだとこれはうまくいかないので、pyvisを使うことにした。
Knowledge Graphが出来たので、次はこのデータに対してクエリを実行するだけ。