検証していないので概念図なのだけれど、たぶん出来るはず。
Azure Database for PostgreSQL Flexible Serverには、pgvectorとazure_aiエクステンションが追加されている。従って、azure_aiエクステンションにAzure OpenAIのエンドポイントとAPIキーを設定すれば、text-embedding-ada-002などを使ってベクトル化して、それをベクトル型のカラムに格納できる。
では、この機能を使ってセマンティック検索をする時にどういう作りにすれば良いのかを考えてみると、以下のようになる。
左側がRAGのベースとなるデータで、これはFunctionsなどを使ってベクトル化したテーブルを作成しておく。水色の❶〜❹のフローがこれに該当する。
一方で右側がユーザーへのインターフェースで、ここではApp ServiceでReactなどでWUIを実装し、ユーザーからの質問をPostgreSQLにINSERTし、かつ得られたベクトルを、水色の❶〜❹のフローで事前に作成しておいたテーブルで検索し、類似度の高いテキストデータを取得する。単に検索であれば、得られたテキストデータをWUIに表示すれば処理は完了するが、さらに赤色の❻のように得られたテキストデータを用いてCompletion APIに回答を生成させることで、自然な文章が回答として返せる(はず)という作り。
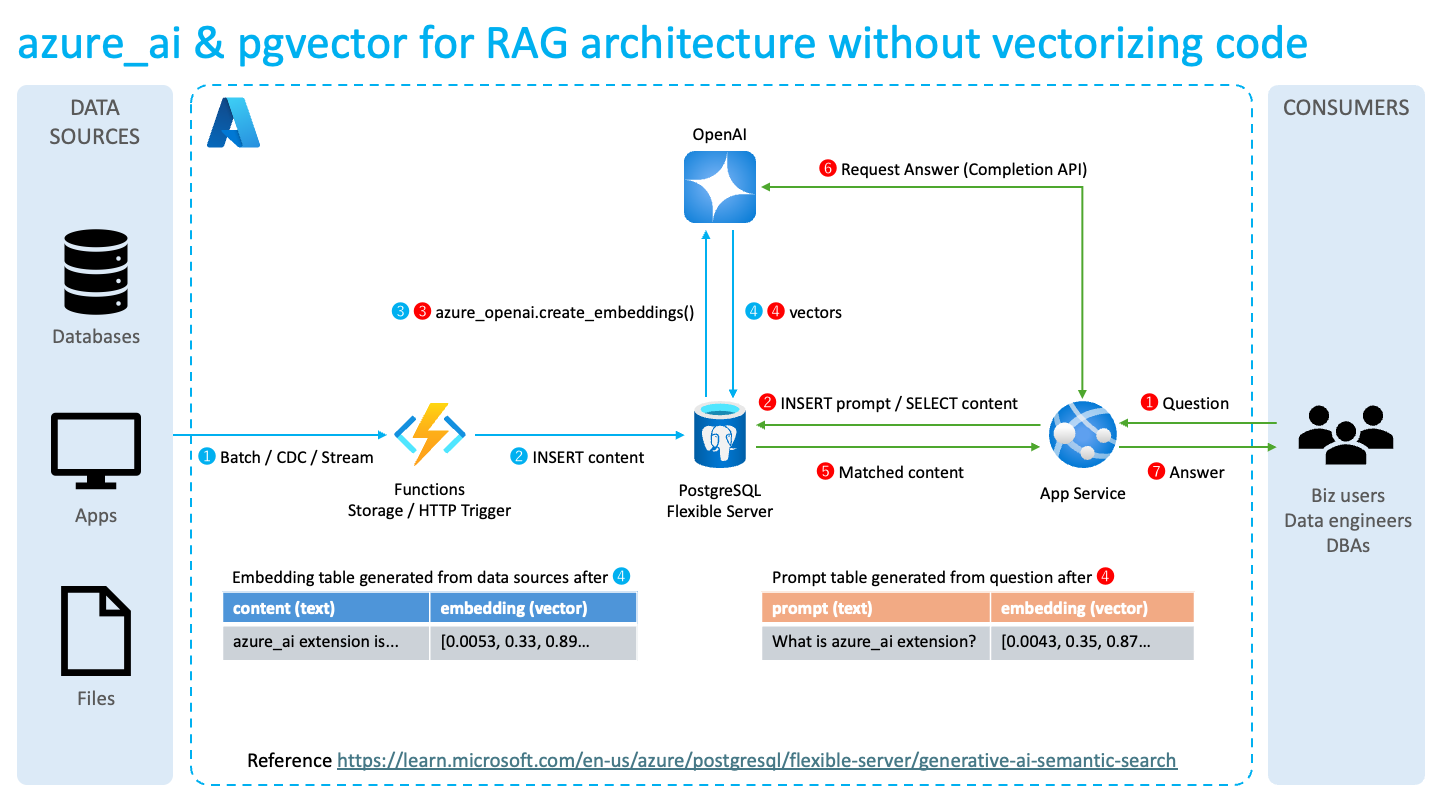
この作りのキモはタイトルにもある通り、ベクトル化をPostgreSQLのazure_aiエクステンションに任せきりに出来る点。azure_openai.craete_embeddings()ではタイムアウトも指定出来るので、App Serviceでタイムアウト時にごめんなさいする処理を入れれば、それっぽく作れるような気がする…。
制約事項として、pgvector 0.5.1は1,536次元までしかベクトル型を検索できない(格納だけなら2,000次元)。ここは多分にPostgreSQLのメモリ消費量にかかってくるので、もっと大きなインスタンスでは次元数を増やせるようにするとか、そういう機能が欲しいところではある。
参考資料: Semantic Search with Azure Database for PostgreSQL – Flexible Server and Azure OpenAI
追記(2024.3.19)GENERATED ALWAYS ASを使ったテーブル定義の参考資料:Introducing the azure_ai extension to Azure Database for PostgreSQL